5.Logstash日志处理应用案例
孙富阳, 江湖人称没人称。多年互联网运维工作经验,曾负责过孙布斯大规模集群架构自动化运维管理工作。擅长Web集群架构与自动化运维,曾负责国内某大型博客网站运维工作。
1.logstash收集app应用日志
1.app日志概述
应用APP日志,主要用来记录用户的操作
[INFO] 2021-12-28 04:53:36 [cn.sfy.main] – DAU|8329|领取优惠券|2021-12-28 03:18:31
[INFO] 2021-12-28 04:53:40 [cn.sfy.main] – DAU|131|评论商品|2021-12-28 03:06:27
APP在生产是真实的系统,目前仅仅是为了学习日志收集、分析、展示,所以九模拟一些用户数据。
2.app日志架构
1.首先通过filebeat读取日志文件中的内容,并且将内容发送个Logstash
2.logstash接收到内容后,将数据转换为结构化数据。然后输出给es数据库
3.Kibaba添加es索引,读取数据,然后再kibana中进行分析,最后进行展示
3.app日志分析实操
1.filebeat配置
[root@es-node3 ~]# cat /etc/filebeat/filebeat.yml
filebeat.inputs:
- type: log
paths:
- /var/log/app.log
enabled: true
output.logstash:
hosts: ["10.0.0.152:5044"]
2.logstash配置
[root@es-node3 ~]# cat /etc/logstash/conf.d/app.conf
input {
beats {
port => 5044
}
}
filter {
mutate {
split => { "message" => "|" }
add_field => {
"UserID" => "%{[message][1]}"
"Action" => "%{[message][2]}"
"Date" => "%{[message][3]}"
}
convert => {
"UserID" => "integer"
"Action" => "string"
"Date" => "string"
}
remove_field => ["headers","message"]
}
date {
match => ["Date", "YYYY-MM-dd HH:mm:ss"]
target => "@timestamp"
timezone => "UTC"
}
}
output {
stdout {
codec => rubydebug
}
}
3.插入一条数据查看结果
[root@es-node3 ~]# echo "[INFO] 2021-12-28 04:53:36 [cn.sfy.main] ? DAU|8329|领取优券|2021-12-28 03:18:31" >> /var/log/app.log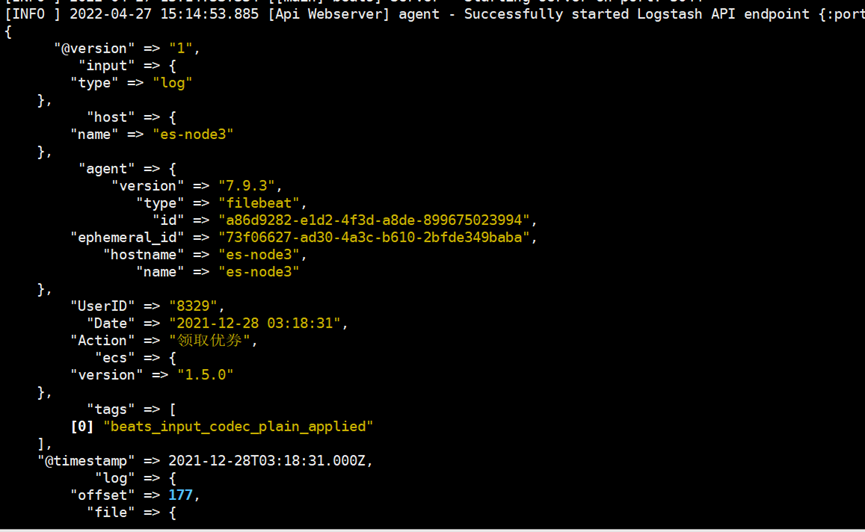
4.经过测试没有问题,现在配置数据打入es数据库
修改logstash配置文件
[root@es-node3 ~]# cat /etc/logstash/conf.d/app.conf
input {
beats {
port => 5044
}
}
filter {
mutate {
split => { "message" => "|" }
add_field => {
"UserID" => "%{[message][1]}"
"Action" => "%{[message][2]}"
"Date" => "%{[message][3]}"
}
convert => {
"UserID" => "integer"
"Action" => "string"
"Date" => "string"
}
remove_field => ["headers","message"]
}
date {
match => ["Date", "YYYY-MM-dd HH:mm:ss"]
target => "@timestamp"
timezone => "UTC"
}
}
output {
elasticsearch {
hosts => ["10.0.0.150:9200","10.0.0.151:9200","10.0.0.152:9200"]
index => "app-logstash-app-%{+yyyy.MM.dd}"
}
}
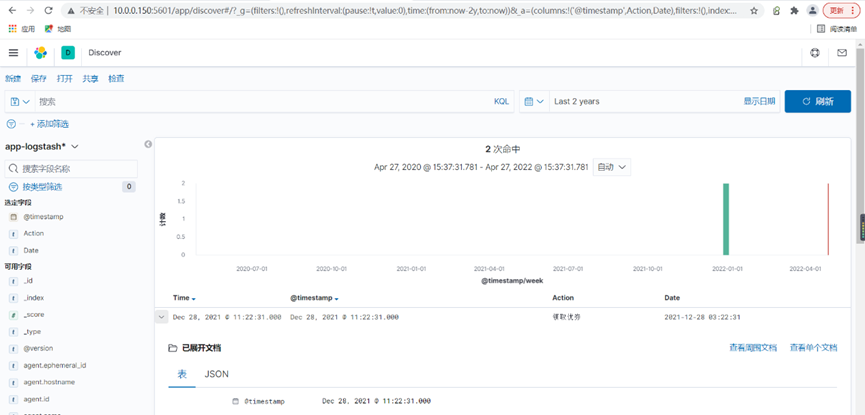
创建测试数据
[root@es-node3 ~]# echo "[INFO] 2021-12-28 04:54:36 [cn.sfy.main] – DAU|8332|领取优券|2021-12-28 03:21:31" >> /var/log/app.log
[root@es-node3 ~]# echo "[INFO] 2021-12-28 04:55:36 [cn.sfy.main] – DAU|8333|领取优券|2021-12-28 03:22:31" >> /var/log/app.log
可以看到刚才创建的数据已经展示出来了
2.Logstash分析Nginx日志
1.Nginx日志收集概述
使用前面所学习到的所有内容,对nginx进行日志分析
221.228.217.171 - - [28/Apr/2022:04:16:48 +0800] "GET /error/ HTTP/1.1" 304 0 "-" "python-requests/2.27.1" "124.248.67.36"
日志格式为nginx默认格式如下:
log_format main '$remote_addr - $remote_user [$time_local] "$request" '
'$status $body_bytes_sent "$http_referer" '
'"$http_user_agent" "$http_x_forwarded_for"';
1.将Nginx普通日志转换为json
2.将Nginx日志的时间格式进行格式化输出
3.将Nginx日志的来源IP进行地域分析
4.将Nginx日志的user-agent字段进行分析
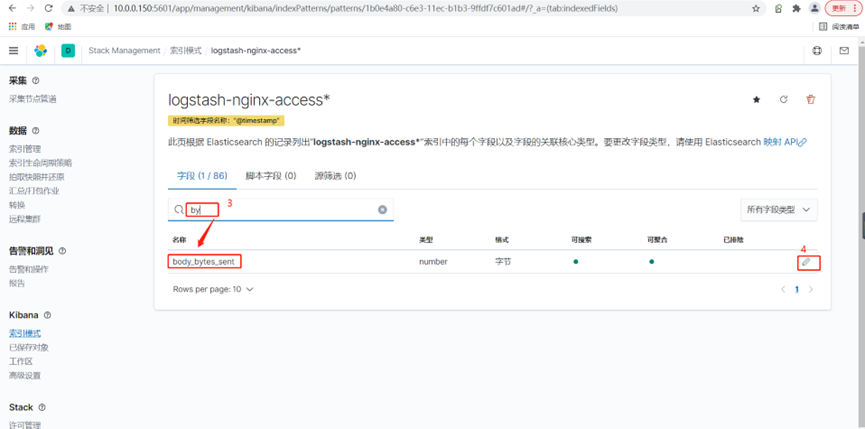
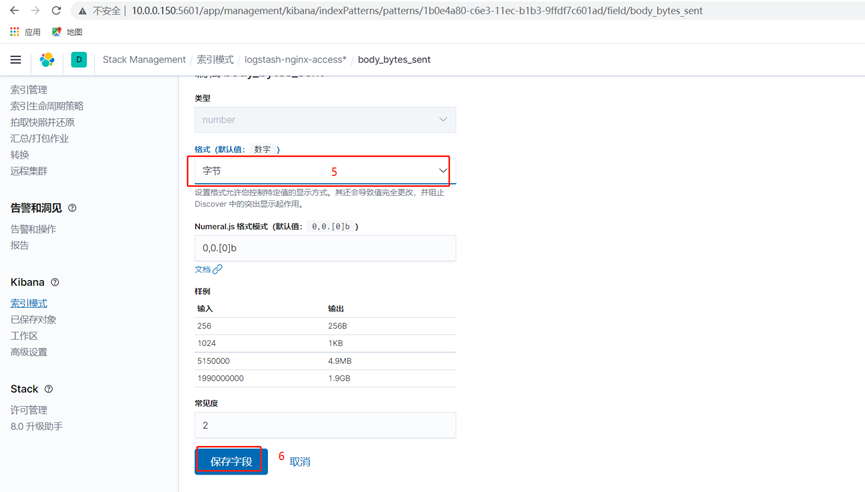
5.将Nginx日志的bytes修改为整数
2.filebeat配置如下
[root@es-node3 ~]# cat /etc/filebeat/filebeat.yml
filebeat.inputs:
- type: log
paths:
- /var/log/nginx.log
enabled: true
tags: ["access"]
- type: log
paths:
- /var/log/error.log
enabled: true
tags: ["error"]
output.logstash:
hosts: ["10.0.0.152:5044"]
# loadbalance: true 多个Logstash的时候开启负载
# worker: 2 #工作线程数 * number of hosts
3.logtash配置如下
###创建grok的匹配
[root@es-node3 ~]# mkdir /usr/local/logstash/patterns -p
[root@es-node3 ~]# cat /usr/local/logstash/patterns/nginx
# URIPARM1 [A-Za-z0-9$.+!*'|(){},~@#%&/=:;_?\-\[\]]*
# URIPATH1 (?:/[A-Za-z0-9$.+!*'(){},~:;=@#%&_\- ]*)+
NGINXACCESS %{IPORHOST:remote_addr} - (%{USERNAME:user}|-) \[%{HTTPDATE:log_timestamp}\] "(?:%{WORD:verb} %{NOTSPACE:request}(?: HTTP/%{NUMBER:httpversion})?|%{DATA:rawrequest})" %{BASE10NUM:http_status} (?:%{BASE10NUM:body_bytes_sent}|-) \"%{GREEDYDATA:http_referrer}\" (?:%{QUOTEDSTRING:user_agent}|-) \"(%{IPV4:http_x_forwarded_for}|-)"
###logstash配置文件
[root@es-node3 ~]# cat /etc/logstash/conf.d/nginx.conf
input {
beats {
port => 5044
}
}
filter {
if "access" in [tags][0] {
grok {
patterns_dir => "/usr/local/logstash/patterns" ###指定pattern匹配grok的路径
match => {
"message" => "%{NGINXACCESS}"
}
}
geoip {
source => "http_x_forwarded_for"
fields => ["country_name","country_code2","timezone","longitude","latitude","continent_code"]
}
date {
# 09/Nov/2020:08:51:50 +0800
match => ["log_timestamp", "dd/MMM/yyyy:HH:mm:ss Z" ]
target => "@timestamp"
timezone => "Asia/Shanghai"
}
useragent {
source => "user_agent"
target => "agent"
}
mutate {
convert => [ "body_bytes_sent", "integer" ]
add_field => { "target_index" => "logstash-nginx-access-%{+YYYY.MM.dd}" }
}
} else if "error" in [tags][0] {
mutate {
add_field => { "target_index" => "logstash-nginx-error-%{+YYYY.MM.dd}" }
}
}
}
output {
elasticsearch {
hosts => ["10.0.0.150:9200","10.0.0.151:9200","10.0.0.152:9200"]
index => "%{[target_index]}"
}
}
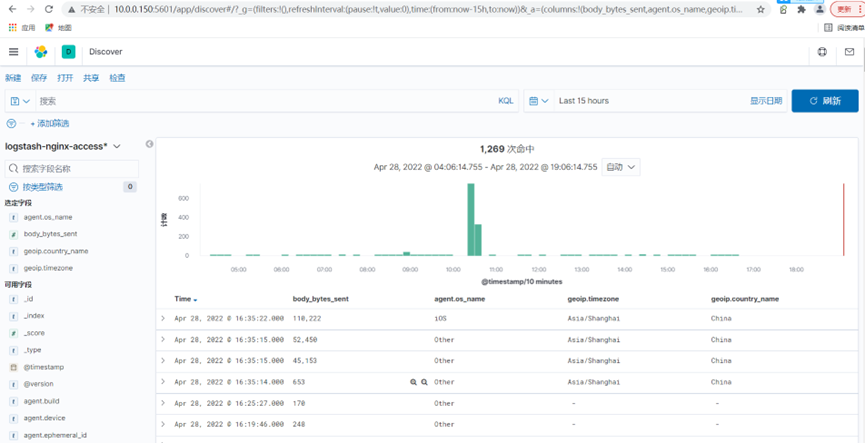
效果图如下
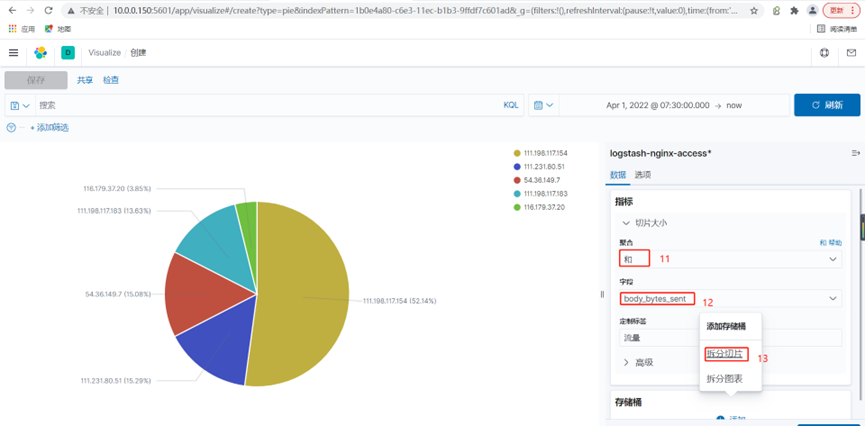
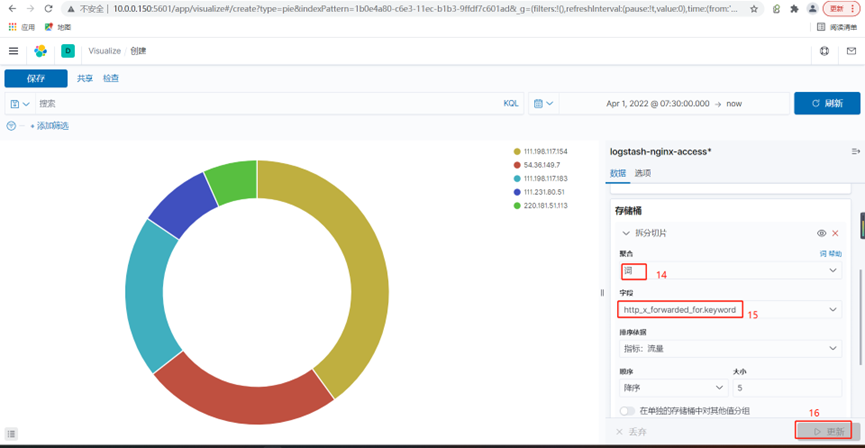
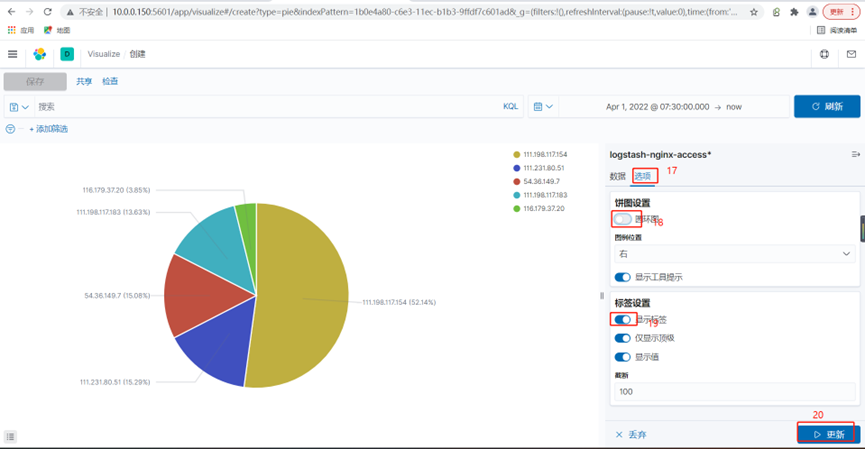
4.使用kibana创建一个每个ip访问的流量的饼图
3.Logstash分析mysql日志
1.MySQL慢日志收集介绍
1.什么是Mysql慢查询日志?
当SQL语句执行时间超过所设定的阈值时,便会记录到指定的日志文件中,所记录内容称之为慢查询日志。2.为什么要收集Mysql慢查询日志?
数据库在运行期间,可能会存在SQL语句查询过慢,那我们如何快速定位、分析哪些SQL语句需要优化处理,又是哪些SQL语句给业务系统造成影响呢?
当我们进行统一的收集分析,SQL语句执行的时间,以及执行的SQL语句,一目了然。
3.如何收集Mysql慢查询日志?
1.安装MySQL
2.开启MySQL慢查询日志记录
3.使用filebeat收集本地慢查询日志路径
2.MySQL慢查询日志收集
1.安装MySQL,并开启慢日志
[root@es-node3 ~]# yum -y install mariadb-server.x86_64
[root@es-node3 ~]# systemctl start mariadb.service
[root@es-node3 ~]# mysql
MariaDB [(none)]> set global slow_query_log=on;
MariaDB [(none)]> set global long_query_time=0.01;
MariaDB [(none)]> set global log_queries_not_using_indexes=1;
#模拟慢日志
MariaDB [(none)]> select sleep(1) user,host from mysql.user;
2.配置filebeat收集mysql日志
[root@es-node3 ~]# cat /etc/filebeat/filebeat.yml
filebeat.inputs:
- type: log
enabled: true
paths:
- /var/lib/mysql/es-node3-slow.log
exclude_lines: ['^\# Time'] #排除无用的行
multiline.pattern: '^\# User'
multiline.negate: true
multiline.match: after
multiline.max_lines: 10000 #默认最大合并500行,可根据实际情况调整
#输出至屏幕,查看是否都写入至Message字段
output.console:
pretty: true
enable: true
3.Logstash处理分析日志
1.filebeat配置,将原来写入es修改为写入logstash
[root@es-node3 ~]# cat /etc/filebeat/filebeat.yml
filebeat.inputs:
- type: log
enabled: true
paths:
- /var/log/mariadb/slow.log
exclude_lines: ['^\# Time'] #排除匹配的行
multiline.pattern: '^\# User'
multiline.negate: true
multiline.match: after
output.logstash:
hosts: ["10.0.0.152:5044"]
2.logstash日志处理思路
1.使用grok插件将mysql慢日志格式化为json格式
2.将timestamp时间转换为本地时间
3.检查json格式是否成功,成功后可以将没用的字段删除
4.最后将输出到屏幕的内容,输出至Elasticsearch集群。
3.logstash配置
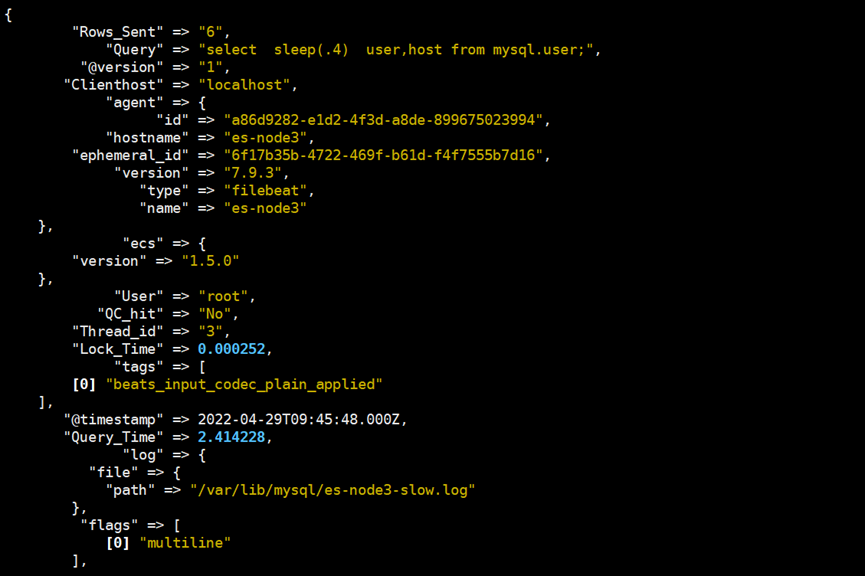
[root@es-node3 ~]# cat /etc/logstash/conf.d/mysql_logstash_es.conf
input {
beats {
port => 5044
}
}
filter {
#将filebeat多行产生的\n替换为空
mutate {
gsub => ["message","\n"," "]
}
grok {
match => { "message" => "(?m)^# User@Host: %{USER:User}\[%{USER-2:User}\] @ (?:(?<Clienthost>\S*) )?\[(?:%{IP:Client_IP})?\] # Thread_id: %{NUMBER:Thread_id:integer}\s+ Schema: (?:(?<DBname>\S*) )\s+QC_hit: (?:(?<QC_hit>\S*) )# Query_time: %{NUMBER:Query_Time}\s+ Lock_time: %{NUMBER:Lock_Time}\s+ Rows_sent: %{NUMBER:Rows_Sent:integer}\s+Rows_examined: %{NUMBER:Rows_Examined:integer} SET timestamp=%{NUMBER:timestamp}; \s*(?<Query>(?<Action>\w+)\s+.*)" }
}
date {
match => ["timestamp","UNIX", "YYYY-MM-dd HH:mm:ss"]
target => "@timestamp"
timezone => "Asia/Shanghai"
}
mutate {
#移除message等字段
remove_field => ["message","input","timestamp"]
#对Query_time Lock_time 格式转换为浮点数
convert => ["Lock_Time","float"]
convert => ["Query_Time","float"]
#添加索引名称
add_field => { "[@metadata][target_index]" => "mysql-logstash-%{+YYYY.MM.dd}" }
}
}
output {
elasticsearch {
hosts => ["10.0.0.150:9200","10.0.0.151:9200","10.0.0.152:9200"]
index => "%{[@metadata][target_index]}"
template_overwrite => true
}
}
由于日志量较少,我就没有输入到es,直接输入到屏幕上了,可以看到效果还是不错的
未经允许不得转载:孙某某的运维之路 » 5.Logstash日志处理应用案例

评论已关闭