8. ELK 引入kafka消息队列解耦
孙富阳, 江湖人称没人称。多年互联网运维工作经验,曾负责过孙布斯大规模集群架构自动化运维管理工作。擅长Web集群架构与自动化运维,曾负责国内某大型博客网站运维工作。
1.消息队列基本介绍
1.什么是消息队列?
消息 Message:比如两个设备进行数据的传输,所传输的数据,都可以称为消息,可以是文本、音频
队列 Queue:是一种”先进先出“的数据结构。类似排队买票、羽毛球筒。
消息队列MQ:是用来保存消息的一个容器。消息队列需要两个功能接口供外部调用,一个是生产、一个是消费。主要是进行数据存储和读取。把数据放到消息队列叫做生产者,从队列里取数据叫做消费者。
2.MQ主要分为两类: 点对点、发布/订阅
共同点
消息的生产者 (Producer)生产消息发送到队列中,然后消息的消费者(Consumer)从队列中读取并消费消息。
不同点
点对点:消息队列 (Queue)、发送者 (Sender)、接收者 (Receiver)
一个生产者生产的消息只能有一个消费者,消息一旦被消费,消息就不在消息队列中了,比如:钉钉的澡堂模式、打电话等。都是消息发送到消息队列后只能被一个接收者接收,当接收完毕消息则销毁。
发布/订阅:消息队列(Queue)、发布者(Publisher)、订阅者(Subscriber)、主题(Topic)
每个消息可以有多个消费者,彼此互不影响,比如:我使用公众号发布一篇文章,关注我的人都能看到,即发布到消息队列的消息能被多个接收者(订阅者)接收。
2.消息队列使用场景
消息队列最主要有三个场景总结为6个字。解耦、异步、削峰
1.解耦
场景说明:用户下单后,订单系统需要通知库存系统。传统的做法是,订单系统调用库存系统的接口。
传统模式的缺点:
1)假如库存系统无法访问,则订单减库存将失败,从而导致订单失败;
2)订单系统与库存系统耦合;
中间件模式:
订单系统:用户下单后,订单系统完将消息写入消息队列,返回用户订单下单成功。
库存系统:订阅下单的消息,获取下单信息,库存系统根据下单信息,进行库存操作。
假如:在下单时库存系统不能正常使用。也不影响正常下单,因为下单后,订单系统写入消息队列就不再关心其他的后续操作了。实现订单系统与库存系统的应用解耦。
2.异步
场景说明:用户注册后,需要发注册邮件和注册短信。将注册信息写入数据库成功后,发送注册邮件,再发送注册短信。以上三个任务全部完成后,返回给客户端。
传统模式的缺点:系统的性能(并发量,吞吐量,响应时间)会有瓶颈。
中间件模式: 将不是必须的业务逻辑,异步处理。
按照以上约定,用户的响应时间相当于是注册信息写入数据库的时间,也就是50毫秒。注册邮件,发送短信写入消息队列后,直接返回,因此写入消息队列的速度很快,基本可以忽略,因此用户的响应时间可能是50ms或55ms。
3.削峰
场景说明:秒杀活动,一般会因为流量过大,导致流量暴增,应用挂掉。
中间件模式:
1.用户的请求,服务器接收后,首先写入消息队列。假如消息队列长度超过最大数量限制,则直接抛弃用户请求或跳转到错误页面。
2.秒杀业务可以根据自身能处理的能力获取消息队列数据,然后做后续处理。这样即使有8000个请求也不会造成秒杀业务奔溃。
3.Kafka基本概述
1.什么是kafka
kafka是一个实时数据处理系统。实时数据处理系统就是数据一旦产生,就要能快速进行处理的系统。对于实时数据处理系统,最常见的就是消息队列。kafka 也是一个MQ消息队列。2.kafka的特点
高吞吐量:可以满足每秒百万级别消息的生产和消费。零拷贝技术、磁盘顺序IO存储
持久性:有一套完善的消息存储机制,确保数据的高效安全的持久化。
分布式:基于分布式的扩展和容错机制,当某一台发生故障失效时,可以实现故障自动转移。
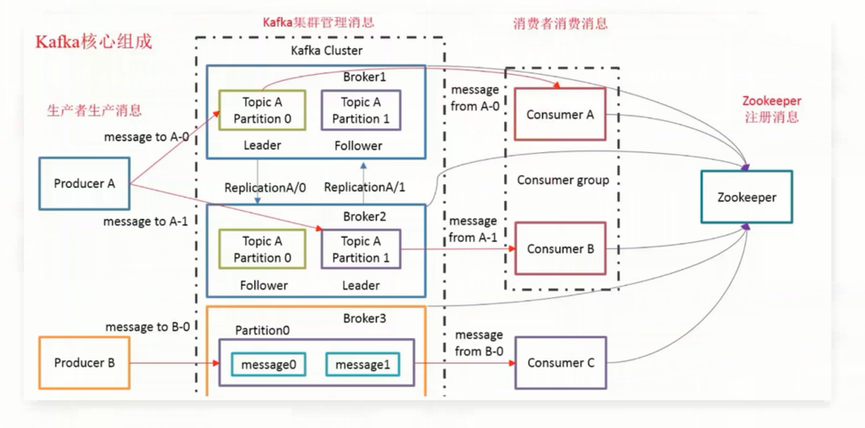
3.kafka基本架构
Broker:kafka集群中包含多个kafka服务节点,每一个kafka服务节点就称为一个broker
Topic: 主题,Kafka将消息分门别类, 每一类的消息称之为(Topic).(Kafka消息数据是存储在硬盘上的)
Partition: 分区,每个Topic包含一个或多个Partition,在创建Topic时指定包含的Partition数量(目的是为了进行分布式存储)
Replication: 副本,每个分区可以有多个副本,分布在不同的Broker上,会选出一个副本作为Leader,所有的读写请求都会通过Leader完成,但Follower只负责备份数据,所有Follower会自动的从Leader中复制数据,当Leader宕机后,会从Follower中选出一个新的Leader继续提供服务,实现故障自动转移。
Message: 消息,是通信的基本单位,每个消息都属于一个Partition
Producer: 消息的生产者,向 Kafka的一个topic发布消息
Consumer: 消息的消费者,订阅 topic并读取其发布的消息
Consumer Group: 每个Consumer属于一个特定的Consumer Group,多个Consumer可以属于同一个 Consumer Group中
Zookeeper: 主要用来存储Kafka的元数据信息,比如:有多少集群节点、主题名称、主要用来协调kafka的正常运行。但发送给Topic本身的消息数据并不存储在ZK中,而存在kafka的磁盘文件中。
4.kafka高性能的原因
1.充分的利用操作系统的缓存;
数据一旦写入到kafka的 buffer, 数据就可以被消费者消费; 消费者通过网卡-->内核缓存区消费;
2.采用了顺序IO落盘; 零拷贝技术
1.落盘:数据写入buffer,但长时间没有被获取;-->操作系统-->fsync--> 落盘; 顺序IO; 能够很快的落盘;
2.读取: 零拷贝技术; 磁盘文件-->内核缓存区; 发送给所有的消费者;
4.Kafka单节点安装及基本使用
1.安装zookeeper
[root@es-node1 ~]# yum install java maven -y
[root@es-node1 ~]# tar xf zookeeper-3.4.11.tar.gz -C /opt/
[root@es-node1 opt]# cd /opt/zookeeper-3.4.11/
[root@es-node1 zookeeper-3.4.11]# cp conf/zoo_sample.cfg conf/zoo.cfg
[root@es-node1 zookeeper-3.4.11]# bin/zkServer.sh start
2.安装kafka
[root@es-node1 ~]# tar xf kafka_2.11-1.0.0.tgz -C /opt/
[root@es-node1 ~]# cd /opt/kafka_2.11-1.0.0/bin/
[root@es-node1 bin]# ./kafka-server-start.sh ../config/server.properties
3.使用kafka创建 topic
[root@es-node1 ~]# cd /opt/kafka_2.11-1.0.0/bin/
[root@es-node1 bin]# ./kafka-topics.sh \
--create \
--zookeeper localhost:2181 \
--replication-factor 1 \
--partitions 3 \
--topic sfy
4.查看topic详情
[root@es-node1 bin]# ./kafka-topics.sh \
--describe \
--zookeeper localhost:2181 \
--topic sfy
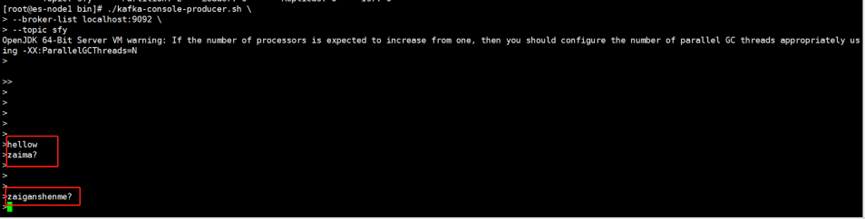
5.producer模拟生产者,产生数据
[root@es-node1 bin]# ./kafka-console-producer.sh \
--broker-list localhost:9092 \
--topic sfy
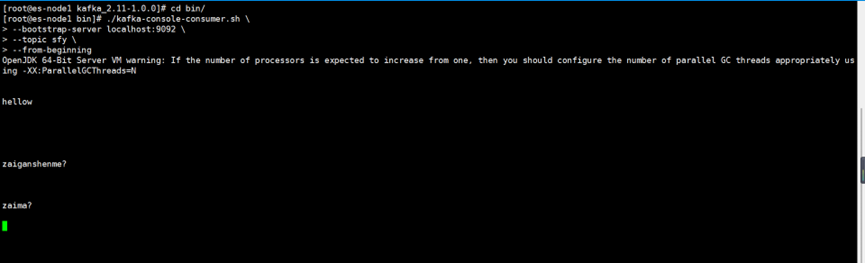
6.consumer模拟消费者,模拟消费
[root@es-node1 bin]# ./kafka-console-consumer.sh \
--bootstrap-server localhost:9092 \
--topic sfy \
--from-beginning
7.删除topic
[root@oldxu-kafka-node1 bin]# ./kafka-topics.sh \
--delete \
--zookeeper localhost:2181 \
--topic sfy
5.Kafka集群搭建
1.安装zookeeper集群
1.安装java并配置zookeeper
yum install -y java maven
[root@es-node1 ~]# cd /opt/zookeeper-3.4.11/conf/
[root@es-node1 conf]# cp zoo_sample.cfg zoo.cfg
[root@es-node1 conf]# cat zoo.cfg
# 服务器之间或客户端与服务器之间维持心跳的时间间隔 tickTime以毫秒为单位。
tickTime=2000
# 集群中的follower服务器(F)与leader服务器(L)之间的初始连接心跳数 10* tickTime
initLimit=10
# 集群中的follower服务器与leader服务器之间请求和应答之间能容忍的最多心跳数 5 * tickTime
syncLimit=5
# 数据保存目录
dataDir=../data
# 日志保存目录
dataLogDir=../logs
# 客户端连接端口
clientPort=2181
# 客户端最大连接数。# 根据自己实际情况设置,默认为60个
maxClientCnxns=60
# 三个接点配置,格式为: server.服务编号=服务地址、LF通信端口、选举端口
server.1=10.0.0.150:2888:3888
server.2=10.0.0.152:2888:3888
server.3=10.0.0.151:2888:3888
2.创建数据存储目录并将配置好的zookeeper拷贝至另外两个节点
[root@es-node1 conf]# mkdir ../data
[root@es-node1 ~]# scp -rp /opt/zookeeper-3.4.11 10.0.0.152:/opt/
[root@es-node1 ~]# scp -rp /opt/zookeeper-3.4.11 10.0.0.151:/opt/
3.在三个节点上写入节点标记(服务编号)并启动zookeeper集群
[root@es-node3 ~]# echo "2" > /opt/zookeeper-3.4.11/data/myid
[root@es-node2 ~]# echo "3" > /opt/zookeeper-3.4.11/data/myid
[root@es-node1 ~]# echo "1" > /opt/zookeeper-3.4.11/data/myid
[root@es-node1 ~]# cd /opt/zookeeper-3.4.11/bin/
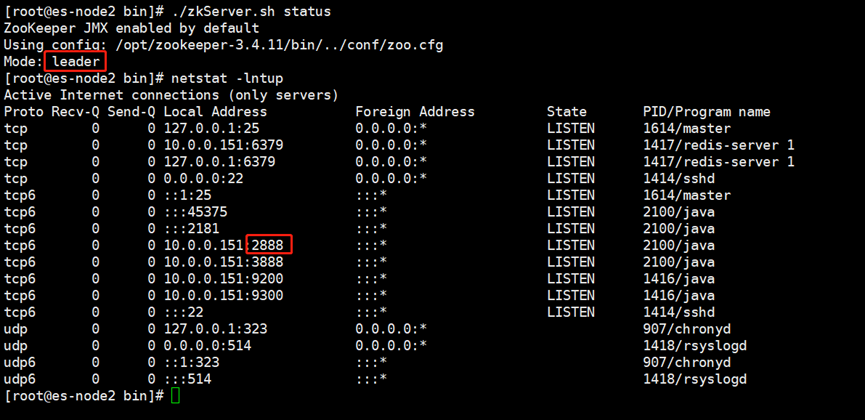
[root@es-node1 bin]# ./zkServer.sh start
[root@es-node2 ~]# cd /opt/zookeeper-3.4.11/bin/
[root@es-node2 bin]# ./zkServer.sh start
[root@es-node3 ~]# cd /opt/zookeeper-3.4.11/bin/
[root@es-node3 bin]# ./zkServer.sh start
###只有leader节点才会监听2888端口
2.安装kafka集群
1.解压并配置kafka
[root@es-node1 ~]# tar xf kafka_2.11-1.0.0.tgz -C /opt/
[root@es-node1 ~]# cd /opt/kafka_2.11-1.0.0/config/
[root@es-node1 ~]# cat /opt/kafka_2.11-1.0.0/config/server.properties
########### Server Basics ############
# broker的id,值为整数,且必须唯一,在一个集群中不能重复
broker.id=1
######### Socket Server Settings ###############
# kafka监听端口,默认9092
listeners=PLAINTEXT://10.0.0.150:9092
# 处理网络请求的线程数量,默认为3个
num.network.threads=3
# 执行磁盘IO操作的线程数量,默认为8个
num.io.threads=8
# socket服务发送数据的缓冲区大小,默认100KB
socket.send.buffer.bytes=102400
# socket服务接受数据的缓冲区大小,默认100KB
socket.receive.buffer.bytes=102400
# socket服务所能接受的一个请求的最大大小,默认为100M
socket.request.max.bytes=104857600
########### Log Basics ################
# kafka存储消息数据的目录
log.dirs=../data
# 每个topic默认的partition
num.partitions=1
# 设置副本数量为3,当Leader的Replication故障,会进行故障自动转移。
default.replication.factor=3
# 在启动时恢复数据和关闭时刷新数据时每个数据目录的线程数量
num.recovery.threads.per.data.dir=1
######### Log Flush Policy ############
# 消息刷新到磁盘中的消息条数阈值
log.flush.interval.messages=10000
# 消息刷新到磁盘中的最大时间间隔,1s
log.flush.interval.ms=1000
######## Log Retention Policy #############
# 日志保留小时数,超时会自动删除,默认为7天
log.retention.hours=168
# 日志保留大小,超出大小会自动删除,默认为1G
#log.retention.bytes=1073741824
# 日志分片策略,单个日志文件的大小最大为1G,超出后则创建一个新的日志文件
log.segment.bytes=1073741824
# 每隔多长时间检测数据是否达到删除条件,300s
log.retention.check.interval.ms=300000
########## Zookeeper ################
# Zookeeper连接信息,如果是zookeeper集群,则以逗号隔开
zookeeper.connect=10.0.0.150:2181,10.0.0.151:2181,10.0.0.152:2181
# 连接zookeeper的超时时间,6s
zookeeper.connection.timeout.ms=6000
2.创建数据存储的目录
[root@es-node1 ~]# mkdir /opt/kafka_2.11-1.0.0/data
[root@es-node1 ~]# scp -rp /opt/kafka_2.11-1.0.0 10.0.0.151:/opt
[root@es-node1 ~]# scp -rp /opt/kafka_2.11-1.0.0 10.0.0.152:/opt
3.修改151和152主机server.properties的broker.id
#node1
broker.id=1
listeners=PLAINTEXT://10.0.0.150:9092
#node2
broker.id=2
listeners=PLAINTEXT://10.0.0.151:9092
#node3
broker.id=3
listeners=PLAINTEXT://10.0.0.152:9092
4.启动kafka集群
[root@es-node1 ~]# export KAFKA_HEAP_OPTS="-Xmx256M -Xms128M" #调整jvm大小
[root@es-node1 bin]#./kafka-server-start.sh ../config/server.properties #启动测试
[root@es-node1 bin]# ./kafka-server-start.sh -daemon ../config/server.properties #放入后台
5.kafka集群验证
#使用kafka创建一个topic
[root@es-node1 bin]# ./kafka-topics.sh \
--create \
--zookeeper 10.0.0.151:2181,10.0.0.152:2181,10.0.0.150:2181 \
--partitions 1 \
--replication-factor 3 \
--topic sfy
#消息发布者测试
./kafka-console-producer.sh \
--broker-list 10.0.0.151:9092,10.0.0.152:9092,10.0.0.150:9092 \
--topic sfy
#消息订阅者测试
./kafka-console-consumer.sh \
--bootstrap-server 10.0.0.151:9092,10.0.0.152:9092,10.0.0.150:9092 \
--topic sfy \
--from-beginning
6.验证kafka容错机制
容错机制,简单就是实现故障转义,比如Leader节点故障,follwer会提升为Leader提供数据的读和写
1.创建一个topic,指定partition分区1,副本数为3
[root@es-node1 bin]# ./kafka-topics.sh \
--create \
--zookeeper 10.0.0.151:2181,10.0.0.152:2181,10.0.0.150:2181 \
--partitions 1 \
--replication-factor 3 \
--topic sfy
2.查看该topic的详情
[root@es-node3 bin]# ../kafka-topics.sh --describe \
--zookeeper 10.0.0.151:2181,10.0.0.152:2181,10.0.0.150:2181 \
--topic sfy

#Topic: 主题名称
#PartitionCount: 分区数量
#ReplicationFactor: 分区副本数
#Leader: 分区Leader是brokerID为1的Kafka
#Replicas: 区副本存储再brokerID (2,3,1)
#Isr: 分区可用的副本brokerID (2,3,1)
3.模拟生产者发送消息,消费者消费消息
#消息发布者测试
./kafka-console-producer.sh \
--broker-list 10.0.0.151:9092,10.0.0.152:9092,10.0.0.150:9092 \
--topic sfy
#消息订阅者测试
./kafka-console-consumer.sh \
--bootstrap-server 10.0.0.151:9092,10.0.0.152:9092,10.0.0.150:9092 \
--topic sfy \
--from-beginning
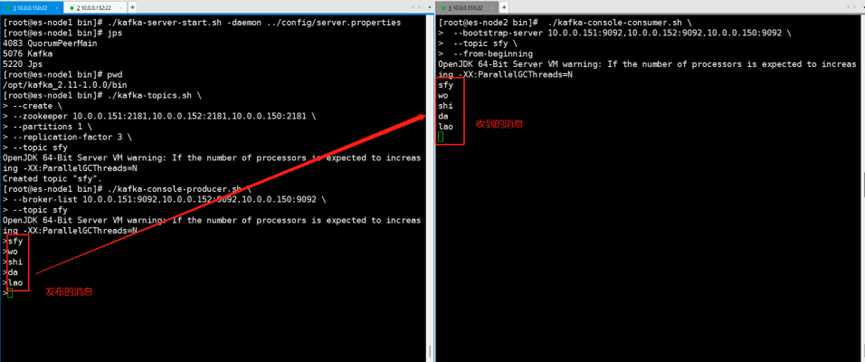
4.模拟Broker为3的节点故障,检查是否会影响生产者和消费者的使用
kill掉节点3的kafka,然后再次查看topic详情
[root@es-node3 bin]# ./kafka-server-stop.sh
[root@es-node3 bin]# ./kafka-topics.sh --describe --zookeeper 10.0.0.151:2181,10.0.0.152:2181,10.0.0.150:2181 --topic sfy

会发现分区可用的副本从原来的(3,2,1)变为了(2,1),也就意味着并不会影响kafka的使用
最后停止该partition为Leader的Kafka节点
[root@es-node1 bin]# ./kafka-server-stop.sh
[root@es-node1 bin]# ./kafka-topics.sh --describe --zookeeper 10.0.0.151:2181,10.0.0.152:2181,10.0.0.150:2181 --topic sfy
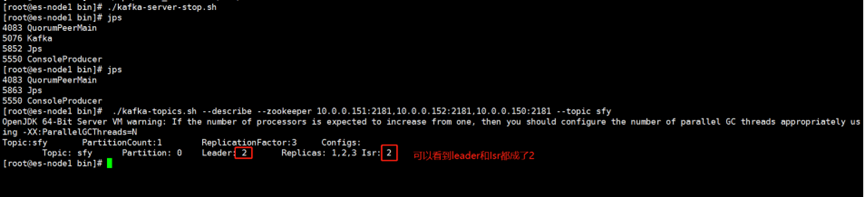
会发现kafka将原来为Replicas的Broker1节点,提升为Leaders,实现了故障自动转移,重启Kafka的Consumer后发现生产与消费一切正常7.ELK对接Kafka
1.filebeat配置
[root@es-node3 bin]# cat /etc/filebeat/filebeat.yml
filebeat.inputs:
- type: log
paths:
- /var/log/nginx.log
enabled: true
tags: ["access"]
- type: log
paths:
- /var/log/error.log
enabled: true
tags: ["error"]
output.kafka:
hosts: ["10.0.0.150:9092","10.0.0.151:9092","10.0.0.152:9092"]
topic: nginx_kafka_prod
2.logstash配置
[root@es-node3 bin]# cat /etc/logstash/conf.d/kafka_Logstash-es.conf
input {
kafka {
bootstrap_servers => "10.0.0.150:9092,10.0.0.151:9092,10.0.0.152:9092"
topics => ["nginx_kafka_prod"]
group_id => "logstash" #消费者组名称
client_id => "node1" #消费者组实例名称
consumer_threads => "3" #理想情况下,您应该拥有与分区数一样多的线程,以实现完美的平衡,线程多于分区意味着某些线程将处于空闲状态
#topics_pattern => "app_prod*" #通过正则表达式匹配要订阅的主题
codec => "json"
}
}
filter {
if "access" in [tags][0] {
grok {
patterns_dir => "/usr/local/logstash/patterns"
match => {
"message" => "%{NGINXACCESS}"
}
}
useragent {
source => "user_agent"
target => "agent"
}
geoip {
source => "http_x_forwarded_for"
fields => ["country_name","country_code2","timezone","longitude","latitude","continent_code"]
}
date {
# 09/Nov/2020:08:51:50 +0800
match => ["log_timestamp", "dd/MMM/yyyy:HH:mm:ss Z" ]
target => "@timestamp"
timezone => "Asia/Shanghai"
}
mutate {
convert => [ "body_bytes_sent", "integer" ]
add_field => { "target_index" => "logstash-nginx-access-%{+YYYY.MM.dd}" }
}
} else if "error" in [tags][0] {
date {
match => ["timestamp","dd/MMM/yyyy:HH:mm:ss Z"]
target => "@timestamp"
timezone => "Asia/Shanghai"
}
mutate {
add_field => { "target_index" => "logstash-nginx-error-%{+YYYY.MM.dd}" }
}
}
}
output {
elasticsearch {
hosts => ["10.0.0.151:9200","10.0.0.152:9200","10.0.0.150:9200"]
index => "%{[target_index]}"
template_overwrite => true
user => "elastic"
password => "iEj4tsQy7iFrdXdJjNY6"
}
stdout {
codec => rubydebug
}
}
3.查看消费者组消费情况
###查询有那些组
[root@es-node1 bin]# ./kafka-consumer-groups.sh --bootstrap-server 10.0.0.151:9092 –list
###指定组查询消费的详情
[root@es-node1 bin]# ./kafka-consumer-groups.sh --describe --bootstrap-server 10.0.0.151:9092 --group logstash
参数解释:
--describe 显示详细信息;
--bootstrap-server 指定kafka连接地址;
--group 指定组名称;
未经允许不得转载:孙某某的运维之路 » 8. ELK 引入kafka消息队列解耦

评论已关闭