14.MySQL主从复制
孙富阳, 江湖人称没人称。多年互联网运维工作经验,曾负责过孙布斯大规模集群架构自动化运维管理工作。擅长Web集群架构与自动化运维,曾负责国内某大型博客网站运维工作。
1.主从同步介绍
两台或者两台以上实例,通过binlog实现数据同步
2.主从同步前提(搭建过程)
1.搭建过程
1.至少两台mysql实例,且server_id,server_uuid不同
可以在配置文件修改uuid,也可以删除/data/3316/data/auto.cnf重启数据库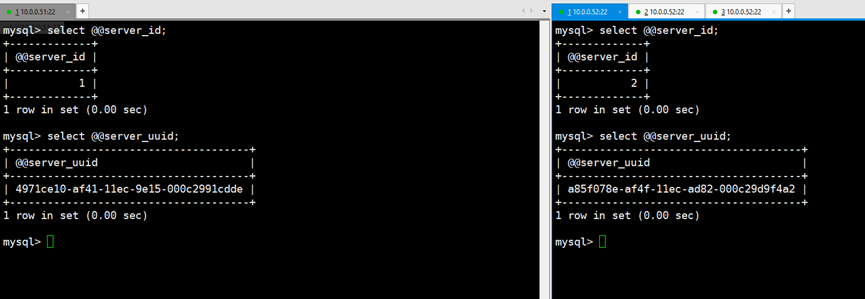
2.主库要开binlog
3.专用的复制用户和权限
mysql> create user repl@'10.0.0.%' identified with mysql_native_password by '123';
mysql> grant replication slave on *.* to repl@'10.0.0.%';
4.预同步主库数据到从库
5.告诉从库连接的起点
CHANGE MASTER TO
MASTER_HOST='10.0.0.51',
MASTER_USER='repl',
MASTER_PASSWORD='123',
MASTER_PORT=3316,
MASTER_LOG_FILE='binlog.000021',
MASTER_LOG_POS=673,
MASTER_CONNECT_RETRY=10;
6.启动复制线程
mysql> start slave;
ps:查看主从复制状态
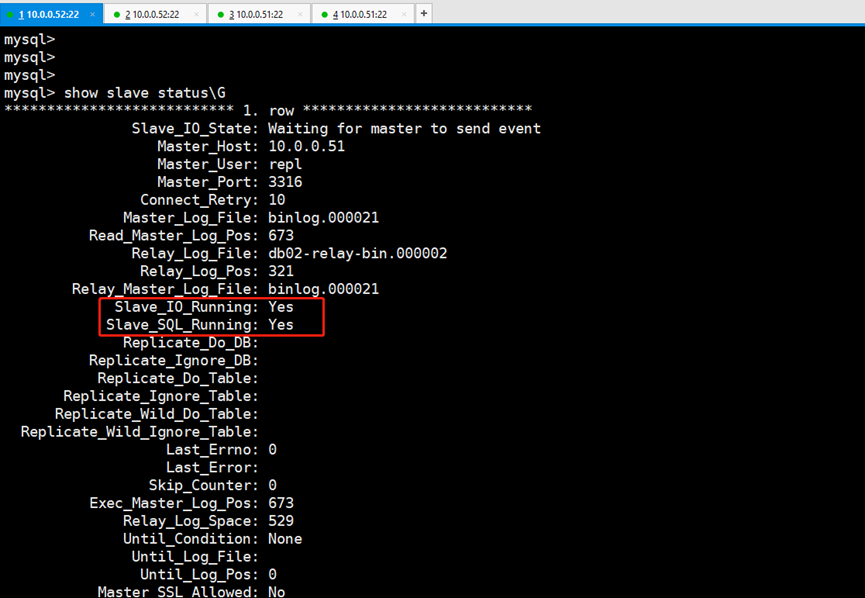
mysql> show slave status\G
重置slave信息:reset slave all;2.传统复制原理
1.涉及到的线程
主库:
dump thread:投递binlog
从库:
IO:请求和接收日志.
SQL:回放日志
2涉及到的文件
主库:
binlog :二进制日志.
从库:
relaylog:中继日志
master.info:主库信息文件(IP,PORT,User ,Password,binlog相关信息)
relaylog.info: SQL回放到的信息.
3主从复制原理
a.从库执行change master to 命令,将主库连接信息和binlog位置信息写入master.info文件或者slave_master_info表中
b.从库执行start slave,启动从库的I0,和SQL线程
c.IO线程读取主库链接信息,连接主库,主库派生dump线程(dump自动监控binlog变化)
d.IO线程根据binlog位置点信息,获取最新的binlog
e.dump截取并投递binlog给从库IO线程,主库不关系投递的结果。
f.IO线程收到binlog(缓存),立即更新master.info或者slave_master_info表
g.缓存binlog数据写入relaylog
h.SQL线程读取relaylog. info或者slave_relay_log info表,获取到上次回放到的位置点,继续往后回放,回放完成后,再次更新relaylog.info信息
i.回放过的relaylog,relay_log_purge线程会定期删除这些日志。
3.主从复制监控
1.监控方法
a.自带命令show slave status \G
b.pt-table-checksum / pt-table-sync /pt-heartbeat
c.orch(orchestrator)
2.自带命令show slave status \G
###主库复制信息
Master_Host: 10.0.0.51
Master_User: repl
Master_Port: 3316
Connect_Retry: 10
Master_Log_File: binlog.000021
Read_Master_Log_Pos: 673
###从库SQL线程已经回放的中继日志信息
Relay_Log_File: db02-relay-bin.000002
Relay_Log_Pos: 321
Relay_Master_Log_File: binlog.000021
Exec_Master_Log_Pos: 673
说明:后两条可以帮助我们判断主从延时的日志量
###主从复制线程故障
Slave_IO_Running: Yes
Slave_SQL_Running: Yes
Last_IO_Errno: 0
Last_IO_Error:
Last_SQL_Errno: 0
Last_SQL_Error:
###过滤复制相关信息
Replicate_Do_DB:
Replicate_Ignore_DB:
Replicate_Do_Table:
Replicate_Ignore_Table:
Replicate_Wild_Do_Table:
Replicate_Wild_Ignore_Table:
###主从之间延时的秒数
Seconds_Behind_Master: 0
###延时从库状态
SQL_Delay: 0
SQL_Remaining_Delay: NULL
###GTID复制
Retrieved_Gtid_Set:
Executed_Gtid_Set:
4.主从复制故障处理
1.IO故障
1.介绍
Slave_io_running connecting/no/yes
Last_IO_error 重点关注报错信息2.常见报错场景
1.通信
外部网络问题
Ip\port\user\passwd
连接数上限
2.请求日志
主库日志缺失
文件名\位置点3.报错解决
1.通信问题
使用复制用户模拟登录,解决登录过程的报错
2.日志
模拟:reset master
处理思路:stop slave
reset slave all
change master to;start slave2.SQL故障
1.介绍
Slave_SQL_Running: YES\No
Last_SQL_Errno:
Last_sQL_Error: 重点关注报错信息
2.报错分析
创建的对象已经存在
册除的对象和修改对象不存在
约束冲突
以上问题原因
从库被误写入了
双主
异步同步
3.解决方案
以主库为准,将从库有冲突的数据删掉.
从库只读
set global super_read_only=1;
mysql set global read only=1;
中间件:读写分离
3.主从延时故障
1.什么是主从延时
主库做的事,从库很久才做
2.监控
Seconds_Behind_Master: 0
Master_Log_File: binlog.000004
Read_Master_Log_Pos:1154
Relay_Master_Log_File: binlog.000004
Exec_Master_Log_Pos: 1154
3.原因
外部因素
硬件差异
资源耗尽
全表扫描
大事务
存储过程
网络问题
主库因素
IO串行工作 group commit
从库因素
单个SQ线程
5.6+多SQL线程 只能按照库级别并发
5.7+增强了多线程SQL 按照事务级别
5.主从复制过滤复制
1.什么是过滤复制?
就是选择性复制
2.应用场景
业务的分离.
部分数据同步

3.如何实现
主库 : 是否记录binlog来控制不常用
binlog_do_db : 白名单
binlog_ignore_db : 黑名单
从库 : SQL线程是否回放来控制
replicate_do_db=world
replicate_ignore_db=test
replicate_do_table=world.city
replicate_ignore_table:test.t100w
replicate_wild_do_table=oldboy.t*
replicate_wild_ignore_table=oldguo.t*
4.配置演练
在线生效:
mysql> stop slave sql_thread;
mysql> change replication filter replicate_do_db = (oldguo, test);
mysql> start slave sql_thread;
永久生效
my.cnf
replicate_do_db = oldguo
replicate_do_db = test
6.延时从库
1.介绍
是我们人为配置的一种特殊从库.人为配置从库和主库延时N小时.
2.为什么要有延时从
物理损坏
主从复制非常擅长解决物理损坏.
逻辑损坏
普通主从复制没办法解决逻辑损坏
3.配置延时从库
SQL线程延时:数据已经写入relaylog中了,SQL线程"慢点"运行
一般企业建议3-6小时,具体看公司运维人员对于故障的反应时间。
stop slave;
CHANGE MASTER TO MASTER_DELAY = 300;
start slave;
4.延时从库应用
1.故障恢复思路
a. 发现问题
b. 停掉从库线程
c. 控制SQL回放日志的截止位置点.
起点:停止SQL线程时,relay最后应用位置
Relay_log_file: db01-relay-bin.000002
Relay_log_pos: 320
终点:误删除之前的position(GTID)
d. 找回数据,快速恢复业务
2.故障模拟及恢复演练
配置从库延迟时间
stop slave;
CHANGE MASTER TO MASTER_DELAY = 300;
start slave;
主库创建数据库
create database relaydb ;
use relaydb;
create table t1(id int);
insert into t1 values(1),(2),(3);
commit;
insert into t1 values(11),(12),(13);
commit;
insert into t1 values(111),(112),(113);
commit;
drop database relaydb;
停止从库SQL线程
stop slave sql_thread;
方法一:
截取日志点位
mysql> show slave status\G查看起点
mysql> show relaylog events in 'db02-relay-bin.000003';查看终点
mysqlbinlog --start-position=233 --stop-position=1448 /data/3316/data/binlog.000011 > /tmp/bin.sql
导入数据
source /tmp/bin.sql
方法二:
stop slave sql_thread;
CHANGE MASTER TO MASTER_DELAY = 0;
START SLAVE SQL_THREAD UNTIL RELAY_LOG_FILE = 'db01-relay-bin.000002', RELAY_LOG_POS = 1576 ;
如果开启GTID,可以按照GTID方式UNTIL
START SLAVE UNTIL SQL_BEFORE_GTIDS = "188be1ed-c84c-11ea-98e7-000c29ea9d83:4";
7.主从数据最终一致性保证---(增强)半同步复制
1.半同步复制-after_commit 和 after_sync
5.5开始支持半同步复制,但是没有GC机制,性能极差,机会没人用
5.6 版本时 ,加入了GC机制,半同步复制开始被接收.使用的是after_commit机制,但是是在redo commit之后进行等待ACK确认.
这里会有一个痛点,如果主库redo commit阶段宕机宕机了,从库又获取到了binlog,会出现从库比主库数据"多"的问题.导致数据不一致.
5.7版本+以后,加入了after_sync机制,在binlog commit(binlog sync disk)阶段,等待从库ACK,不管谁宕机,都能保证最终一致性.
另外:
不管哪种方式,还会出现,如果ACK超时,会被切换为异步复制的模式.还是有数据不一致的风险.
如果公司能容忍,可以使用这种架构,建议使用增强半同步+GTID模式.
如果不能容忍,可以使用MGR PXC .
2.增强半同步复制配置
1.加载插件
INSTALL PLUGIN rpl_semi_sync_master SONAME 'semisync_master.so';
INSTALL PLUGIN rpl_semi_sync_slave SONAME 'semisync_slave.so';
2.查看是否加载成功
show plugins;
启动:
SET GLOBAL rpl_semi_sync_master_enabled = 1;
SET GLOBAL rpl_semi_sync_slave_enabled = 1;
3.重启从库上的IO线程
STOP SLAVE IO_THREAD;
START SLAVE IO_THREAD;
4.查看是否在运行
show status like 'Rpl_semi_sync_master_status';
show status like 'Rpl_semi_sync_slave_status';
5.其他的优化参数
show variables like '%semi%';
rpl_semi_sync_master_enabled =ON
rpl_semi_sync_master_timeout =1000
rpl_semi_sync_master_trace_level =32
rpl_semi_sync_master_wait_for_slave_count =1
rpl_semi_sync_master_wait_no_slave =ON
rpl_semi_sync_master_wait_point =AFTER_SYNC
rpl_semi_sync_slave_enabled =ON
rpl_semi_sync_slave_trace_level =32
mysql> set global binlog_group_commit_sync_delay =1;
mysql> set global binlog_group_commit_sync_no_delay_count =1000;
8.GTID复制
1.GTID介绍
GTID(Global Transaction ID)是对于一个已提交事务的唯一编号,并且是一个全局(主从复制)唯一的编号。
它的官方定义如下:
GTID =server_uuid : transaction_id
7E11FA47-31CA-19E1-9E56-C43AA21293967:29
什么是sever_uuid,和Server-id 区别?
核心特性: 全局唯一,具备幂等性
2.GTID核心参数
重要参数:
gtid-mode=on
enforce-gtid-consistency=true
log-slave-updates=1
gtid-mode=on --启用gtid类型,否则就是普通的复制架构
enforce-gtid-consistency=true --强制GTID的一致性
log-slave-updates=1 --slave更新是否记入日志
3.GTID复制配置过程
1.清理环境
pkill mysqld
\rm -rf /data/3306/data/*
\rm -rf /data/3306/binlog/*
\mv /etc/my.cnf /tmp
mkdir -p /data/3306/data /data/3306/binlog/
chown -R mysql.mysql /data/*
2.准备配置文件
主库db01:
cat > /etc/my.cnf <<EOF
[mysqld]
basedir=/usr/local/mysql/
datadir=/data/3306/data
socket=/tmp/mysql.sock
server_id=51
port=3306
secure-file-priv=/tmp
log_bin=/data/3306/binlog/mysql-bin
binlog_format=row
gtid-mode=on
enforce-gtid-consistency=true
log-slave-updates=1
[mysql]
prompt=db01 [\\d]>
EOF
slave1(db02):
cat > /etc/my.cnf <<EOF
[mysqld]
basedir=/usr/local/mysql
datadir=/data/3306/data
socket=/tmp/mysql.sock
server_id=52
port=3306
secure-file-priv=/tmp
log_bin=/data/3306/binlog/mysql-bin
binlog_format=row
gtid-mode=on
enforce-gtid-consistency=true
log-slave-updates=1
[mysql]
prompt=db02 [\\d]>
EOF
slave2(db03):
cat > /etc/my.cnf <<EOF
[mysqld]
basedir=/usr/local/mysql
datadir=/data/3306/data
socket=/tmp/mysql.sock
server_id=53
port=3306
secure-file-priv=/tmp
log_bin=/data/3306/binlog/mysql-bin
binlog_format=row
gtid-mode=on
enforce-gtid-consistency=true
log-slave-updates=1
[mysql]
prompt=db03 [\\d]>
EOF
3.初始化数据并启动数据库
mysqld --initialize-insecure --user=mysql --basedir=/usr/local/mysql --datadir=/data/3306/data
/etc/init.d/mysqld start4.构建主从
master:51
slave:52,53
# 51:
create user repl@'10.0.0.%' identified with mysql_native_password by '123';
grant replication slave on *.* to repl@'10.0.0.%' ;
# 52\53:
change master to
master_host='10.0.0.51',
master_user='repl',
master_password='123' ,
MASTER_AUTO_POSITION=1;
start slave;
注意:
如果是已经运行很久的数据库,需要构建从库,都是需要备份恢复主库数据后再开启主从的。
mysqldump来讲,不要加--set-gtid-purged=OFF功能。
9.多源复制(MSR Multi Source Replication): OLAP (在线分析处理)
1.多源复制介绍
5.7以上版本,需要开gtid复制
| 主机角色 | 地址 | 端口 |
| -------- | --------- | ---- |
| Master1 | 10.0.0.51 | 3306 |
| Master2 | 10.0.0.52 | 3306 |
| Slave | 10.0.0.53 | 3306 |
2.配置过程
1.GTID环境准备:略,参考8GTID复制
2.配置多源复制
CHANGE MASTER TO MASTER_HOST='10.0.0.51',MASTER_USER='repl', MASTER_PASSWORD='123', MASTER_AUTO_POSITION=1 FOR CHANNEL 'Master_1';
CHANGE MASTER TO MASTER_HOST='10.0.0.52',MASTER_USER='repl', MASTER_PASSWORD='123', MASTER_AUTO_POSITION=1 FOR CHANNEL 'Master_2';
start slave for CHANNEL 'Master_1';
start slave for CHANNEL 'Master_2';
3.多源复制监控
db03 [(none)]>SHOW SLAVE STATUS FOR CHANNEL 'Master_1'\G
db03 [(none)]>SHOW SLAVE STATUS FOR CHANNEL 'Master_2'\G
select * from performance_schema.replication_connection_configuration\G
SELECT * FROM performance_schema.replication_connection_status WHERE CHANNEL_NAME='master_1'\G
select * from performance_schema.replication_applier_status_by_worker;
4.多源复制配置过滤
mysql> CHANGE REPLICATION FILTER REPLICATE_WILD_DO_TABLE = ('db1.%') FOR CHANNEL "master_1";
mysql> CHANGE REPLICATION FILTER REPLICATE_WILD_DO_TABLE = ('db2.%') FOR CHANNEL "master_2";
未经允许不得转载:孙某某的运维之路 » 14.MySQL主从复制

评论已关闭