5.k8s的数据持久化存储
孙富阳, 江湖人称没人称。多年互联网运维工作经验,曾负责过孙布斯大规模集群架构自动化运维管理工作。擅长Web集群架构与自动化运维,曾负责国内某大型博客网站运维工作。
1.为什么需要持久化
之前讲到的部署wordpress,当我们删除了数据库的容器后,再次访问部署的wordpress发现,需要从头再安装一遍,这是因为数据库容器的数据被删除了
为了解决容器被删除后数据不丢失,则引入了存储类型,类似于docker中的数据卷
2.数据卷概述
数据卷:
(1)kubernetes中的Volume提供了在容器中挂载外部存储的能力;
(2)Pod需要设置卷来源(po.spec.volumes)和挂载点(po.spec.containers.volumeMounts)两个信息后才可以使用相应的volume;
数据卷类型大致分类:
本地数据卷:hostPath,emptyDir等。
网络数据卷:NFS,Ceph,GlusterFS等。
公有云:AWS,EBS等;
K8S资源:configmap,secret等。
除了上述提到的数据类型分类,但官方文档却要比上述描述的数据卷类型多得多,如下图所示。
推荐阅读:https://kubernetes.io/zh/docs/concepts/storage/volumes/
3.emptyDir存储类型(多个Pod不能使用该类型进行数据共享,但同一个Pod的多个容器可以基于该类型进行数据共享)
1.emptyDir概述
emptyDir数据卷:
是一个临时存储卷,与Pod生命周期绑定在一起,如果Pod删除了,这意味着数据卷也会被删除。
emptyDir的作用:
(1)可以实现持久化的功能;
(2)多个Pod之间不能通信数据,但是同一个Pod的多个容器是可以实现数据共享的;
(3)随着Pod的生命周期而存在,当我们删除Pod时,其数据也会被随之删除。
emptyDir的应用场景(同一个Pod中各个容器之间数据的共享):
(1)缓存空间,例如基于磁盘的归并排序;
(2)为耗时较长的计算任务提供检查点,以便任务能方便地从崩溃前状态恢复执行;
(3)存储Web服务器的访问日志及错误日志等信息;
推荐阅读:https://kubernetes.io/docs/concepts/storage/volumes/#emptydir
温馨提示:
使用emptyDir持久化数据时,删除容器并不会删除数据,因为容器删除并不能说明Pod被删除哟
2.修改deployment资源并使用emptyDir
[root@k8s-master chijiuhua]# cat deploy-emptyDir.yaml
apiVersion: extensions/v1beta1
kind: Deployment
metadata:
name: mysql
namespace: kube-system
spec:
replicas: 1
template:
metadata:
labels:
app: mysql
spec:
volumes:
- name: data
emptyDir: {} # 我们无需为emptyDir指定任何参数,通常写个"{}"即可,表示创建的是一个空目录。
containers:
- name: mysql
volumeMounts:
- name: data # 注意哈,该名称必须在上面的"volumes"的name字段中存在哟~
mountPath: /var/lib/mysql # 指定挂载到容器的位置
image: k8s-master:5000/mysql:5.7
ports:
- containerPort: 3306
env:
- name: MYSQL_ROOT_PASSWORD
value: somewordpress
- name: MYSQL_DATABASE
value: wordpress
- name: MYSQL_USER
value: wordpress
- name: MYSQL_PASSWORD
value: wordpress
---
apiVersion: v1
kind: Service #简称svc
metadata:
name: musql-svc
namespace: kube-system
spec:
clusterIP: 10.254.86.101
type: ClusterIP
ports:
- port: 3306
targetPort: 3306 #pod port
selector:
app: mysql
---
apiVersion: extensions/v1beta1
kind: Deployment
metadata:
name: wordpress
spec:
replicas: 1
template:
metadata:
labels:
app: wordpress
spec:
containers:
- name: wordpress
image: k8s-master:5000/wordpress:latest
ports:
- containerPort: 80
env:
- name: WORDPRESS_DB_HOST
value: musql-svc.kube-system.svc.cluster.local
- name: WORDPRESS_DB_USER
value: wordpress
- name: WORDPRESS_DB_PASSWORD
value: wordpress
---
apiVersion: v1
kind: Service #简称svc
metadata:
name: wordpress-svc
spec:
type: NodePort
ports:
- port: 80
nodePort: 31001
targetPort: 80 #pod port
selector:
app: wordpress
[root@k8s-master chijiuhua]# kubectl apply -f deploy-emptyDir.yaml
###停止容器再次访问web页面发现数据还在,不需要重新安装wordpress
[root@k8s-node-2 ~]# docker container stop k8s_mysql.78d4a503_mysql-2682814966-ldbkh_kube-system_4080198f-ba28-11ec-a005-000c2946ccb6_33371b35
4.HostPath存储类型(可以解决同一个Node节点的多个Pod数据共享,但多个Pod不在同一个Node节点时则无法通过HostPath来查找数据)
1.hostPath数据卷概述
hotsPath数据卷:
挂载Node文件系统(Pod所在节点)上文件或者目录到Pod中的容器。
如果Pod删除了,宿主机的数据并不会被删除,这一点是否感觉和咱们的数据卷有异曲同工之妙呢?
应用场景:
Pod中容器需要访问宿主机文件。
推荐阅读:https://kubernetes.io/docs/concepts/storage/volumes/#hostpath
2.修改deployment资源并使用hostPath
[root@k8s-master chijiuhua]# cat deploy-mysql-hostPath.yaml
apiVersion: extensions/v1beta1
kind: Deployment
metadata:
name: mysql
namespace: kube-system
spec:
replicas: 1
template:
metadata:
labels:
app: mysql
spec:
volumes:
- name: data
hostPath: ###指定持久化类型为hostPath
path: /data/mysql
- name: log
emptyDir: {}
containers:
- name: mysql
volumeMounts:
- name: data # 注意哈,该名称必须在上面的"volumes"的name字段中存在哟~
mountPath: /var/lib/mysql # 指定挂载到容器的位置
image: k8s-master:5000/mysql:5.7
ports:
- containerPort: 3306
env:
- name: MYSQL_ROOT_PASSWORD
value: somewordpress
- name: MYSQL_DATABASE
value: wordpress
- name: MYSQL_USER
value: wordpress
- name: MYSQL_PASSWORD
value: wordpress
[root@k8s-master chijiuhua]# kubectl apply -f deploy-mysql-hostPath.yaml
可以看到数据目录被自动创建出来并持久化了
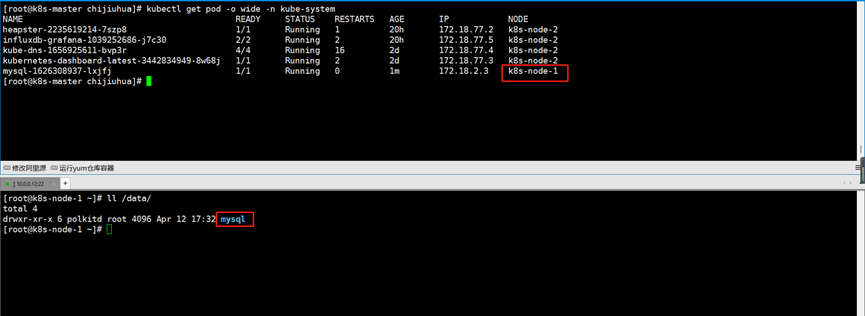
5.NFS存储类型(适合不同的node节点的Pod共享存储,但存在单点故障)
1.NFS数据卷概述
NFS数据卷:
提供对NFS挂载支持,可以自动将NFS共享路径挂载到Pod中。
NFS:
英文全称为"Network File System"(网络文件系统),是由SUN公司研制的UNIX表示层协议(presentation layer protocol),能使使用者访问网络上别处的文件就像在使用自己的计算机一样。
NFS是一个主流的文件共享服务器,但存在单点故障,我们需要对数据进行备份哟,如果有必要可以使用分布式文件系统哈。
推荐阅读:https://kubernetes.io/docs/concepts/storage/volumes/#nfs
2.master节点搭建NFS服务
[root@k8s-master ~]# yum -y install nfs-utils
[root@k8s-master ~]# cat /etc/exports
/data/kubernetes *(rw,no_root_squash)
[root@k8s-master ~]# mkdir -p /data/kubernetes
[root@k8s-master ~]# systemctl start nfs && systemctl enable nfs
[root@k8s-node-1 ~]# yum -y install nfs-utils.x86_64
[root@k8s-node-2 ~]# yum -y install nfs-utils.x86_64
3.修改deployment资源并使用NFS服务
[root@k8s-master chijiuhua]# cat deploy-wordpress-nfs.yaml
apiVersion: extensions/v1beta1
kind: Deployment
metadata:
name: wordpress
spec:
replicas: 1
template:
metadata:
labels:
app: wordpress
spec:
volumes:
- name: nfs
nfs: ###指定持久化类型为nfs
server: k8s-master
path: /data/kubernetes
- name: log
emptyDir: {}
containers:
- name: wordpress
volumeMounts:
- name: nfs
mountPath: /var/www/html
image: k8s-master:5000/wordpress:latest
ports:
- containerPort: 80
env:
- name: WORDPRESS_DB_HOST
value: musql-svc.kube-system.svc.cluster.local
- name: WORDPRESS_DB_USER
value: wordpress
- name: WORDPRESS_DB_PASSWORD
value: wordpress
[root@k8s-master chijiuhua]# kubectl apply -f deploy-wordpress-nfs.yaml
6.PV和PVC的基本使用
1.持久化数据卷(persistent volume,简称"pv")和持久化数据卷声明(persistent volume claim,简称"pvc")的区别
什么是pv:
全称为:"persistent volume",属于k8s集群的全局资源,因此并不支持命名空间(namespace)。
该资源对象本身并不负责数据的真实存储,而是负责和后端存储进行关联,每个pv都有提前定义好的存储能力。
持久卷是对存储资源数据卷(volume)创建和使用的抽象,使得存储作为集群中的资源管理。
这样我们就可以对数据卷的使用空间,读写权限做一个基本的权限管控,而不是放任Pod使用所有的数据卷资源。
pv的作用:
PV解决了企业对于存储的依赖问题,比如A公司使用的是nfs作为存储,而B公司使用的是cephfs作为存储,对于运维人员而言可能需要手动维护不同的组件,而一旦使用pv对存储资源进行抽象后,在迁移服务时就无需关心集群底层存储使用的资源,而是直接使用pv即可。
简而言之,就是实现了后端存储的权限管控(rw,ro),存储能力(比如使用多大的存储空间)以及后端存储卷(volumes)存储类型的应用解耦。
什么是pvc:
全称为:"persistent volume claim", 属于k8s集群某一个namespace的局部资源。
该资源对象本身并不负责数的真实存储,而是显式声明需要使用的存储资源需求。
pvc的作用:
让用户不需要关心具体的Volume实现细节。pvc的一个最重要的作用就是去关联符合条件的pv,从而实现对存储资源的使用。
推荐阅读:https://kubernetes.io/docs/concepts/storage/persistent-volumes/
温馨提示:
(1)全局资源指的是所有的namespace都能看到该资源,很明显是全局唯一的。
(2)局部资源指的是该资源只属于某个namespace哟。
(3)pv和pvc均属于k8s资源,而k8s的所有资源通常都支持打标签的哟
2.创建PV资源
(1)创建pv的存储目录,注意该目录是NFS的挂载目录
mkdir -pv /data/kubernetes/pv0{1,2,3}
(2)编写pv的资源清单
[root@k8s-master pv]# cat 01-pv.yaml
apiVersion: v1
kind: PersistentVolume
metadata:
name: pv01
labels:
type: ssd
spec:
capacity: # 定义PV存储容量的大小
storage: 10Gi
accessModes: # 指定访问模式
- ReadWriteMany
persistentVolumeReclaimPolicy: Recycle # 指定PV的回收策略
nfs: # 指定PV后端的支持存储设备类型
path: "/data/kubernetes/pv01"
server: k8s-master
readOnly: false
[root@k8s-master pv]# cat 02-pv.yaml
apiVersion: v1
kind: PersistentVolume
metadata:
name: pv02
labels:
type: ssd
spec:
capacity: # 定义PV存储容量的大小
storage: 30Gi
accessModes: # 指定访问模式
- ReadWriteMany
persistentVolumeReclaimPolicy: Recycle # 指定PV的回收策略
nfs: # 指定PV后端的支持存储设备类型
path: "/data/kubernetes/pv02"
server: k8s-master
readOnly: false
[root@k8s-master pv]# cat 03-pv.yaml
apiVersion: v1
kind: PersistentVolume
metadata:
name: pv03
labels:
type: ssd
spec:
capacity: # 定义PV存储容量的大小
storage: 50Gi
accessModes: # 指定访问模式
- ReadWriteMany
persistentVolumeReclaimPolicy: Recycle # 指定PV的回收策略
nfs: # 指定PV后端的支持存储设备类型
path: "/data/kubernetes/pv03"
server: k8s-master
readOnly: false
(3)创建pv资源
[root@k8s-master pv]# kubectl apply -f .

温馨提示:
我们在任意的名称空间都能看到PV资源哟,因为它是全局资源!
NAME:有关PV资源的名称。
CAPACITY:该PV资源的容量大小。
ACCESSMODES(访问模式):是用来对PV进行访问模式的设置,用于描述用户应用对存储资源的访问权限,访问权限包括以下几种方式:
ReadWriteOnce(RWO):读写权限,但是只能被单个节点挂载。
ReadOnlyMany(ROX):只读权限,可以被多个节点挂载。
ReadWriteMany(RWX):读写权限,可以被多个节点挂载。
ReadWriteOncePod:卷可以由单个Pod以读写方式挂载。这仅支持CSI卷和Kubernetes 1.22+版。
RECLAIMPOLICY(回收策略):
目前较新版本中PV支持的策略有三种:
Retain(保留):保留数据,需要管理员手工清理数据,这是默认策略哟。
Recycle(回收):清除PV中的数据,效果相当于执行"rm -rf /data/kubernetes/*"。
Delete(删除):与PV相连的后端存储同时删除。
STATUS(状态):一个PV的生命周期中,可能会处于四种不同的阶段:
Available(可用):表示可用状态,还未被任何PVC绑定。
Bound(已绑定):表示PV已经被PVC绑定。
Released(已释放): PVC被删除,但是资源还未被集群重新声明。换句话说,这种状态下PV是不可重新分配的,需要手动清理保留的数据(因为默认的回收策略是"Retain")。
Failed(失败):表示该PV的自动回收失败。
CLAIM:被那个pvc声明使用。
REASON:PV故障原因。
AGE:资源创建的时间。
参考链接:https://kubernetes.io/docs/concepts/storage/persistent-volumes/#access-modes
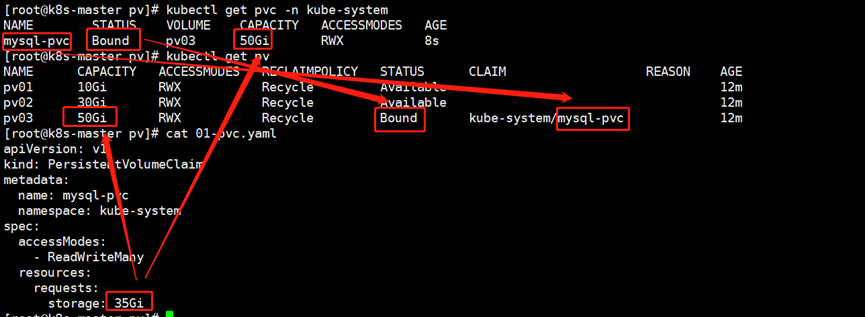
3.创建PVC资源
[root@k8s-master pv]# cat 01-pvc.yaml
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: mysql-pvc
namespace: kube-system
spec:
accessModes:
- ReadWriteMany
resources:
requests:
storage: 35Gi
[root@k8s-master pv]# kubectl apply -f 01-pvc.yaml
温馨提示:
(1)当我们创建的PVC申请的存储大小要小于PV现有存储大小时,K8S会自动评估PVC和与哪一个后端PV进行绑定(Bound),如果pvc找不到合适的PV则pvc始终会停留在"Pending"状态哟~
(2)如下图所示,本案例PVC仅申请了35G内存,但实际上PVC会自动去关联全局资源,匹配最合适的PV,这个过程是由K8s集群自动实现的,无需运维人员手动绑定,绑定成功请注意观察PV和PVC的状态均为"Bound"。
(3)如下图所示,如果将PVC申请的数量过大(本案例是32GB),就会导致PVC无法自动关联全局PV资源,因此PVC的状态始终为"Pending",因为此时并没有一个PV的存储能力能够满足该pvc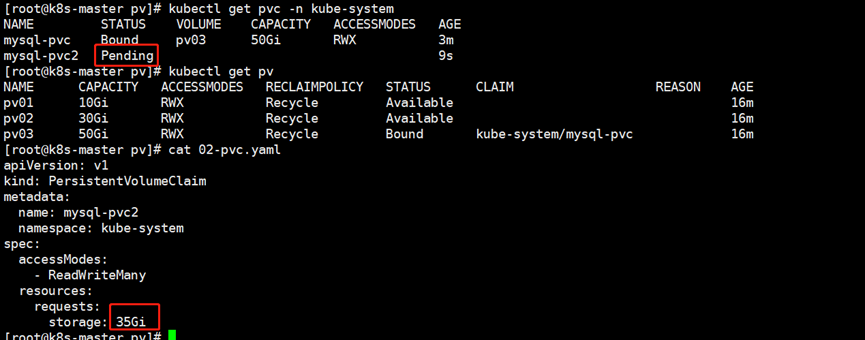
4.mysql的deployment资源使用PVC资源
[root@k8s-master pv]# cat deploy-pvc.yaml
apiVersion: extensions/v1beta1
kind: Deployment
metadata:
name: mysql
namespace: kube-system
spec:
replicas: 1
template:
metadata:
labels:
app: mysql
spec:
volumes:
- name: mysql-pvc
persistentVolumeClaim:
claimName: mysql-pvc # 指定PVC的名称,注意要创建的Pod的名称空间中必须存在该PVC哟~
readOnly: false # PVC是否只读,默认值就为false,如果想要只读请设置为"true"
- name: log
emptyDir: {}
containers:
- name: mysql
volumeMounts:
- name: mysql-pvc # 注意哈,该名称必须在上面的"volumes"的name字段中存在哟~
mountPath: /var/lib/mysql # 指定挂载到容器的位置
image: k8s-master:5000/mysql:5.7
ports:
- containerPort: 3306
env:
- name: MYSQL_ROOT_PASSWORD
value: somewordpress
- name: MYSQL_DATABASE
value: wordpress
- name: MYSQL_USER
value: wordpress
- name: MYSQL_PASSWORD
value: wordpress
[root@k8s-master pv]# kubectl apply -f deploy-pvc.yaml
通过describe数据库的pod可以看到挂载点,同时检查数据,发现已经被持久化过来了
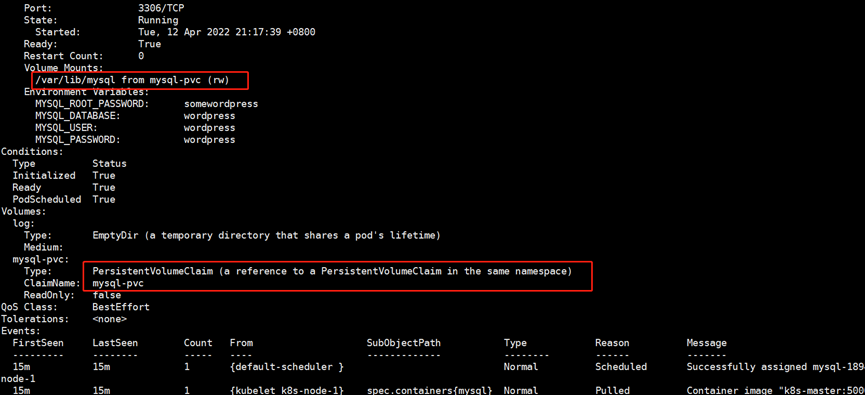
7.PV资源的回收
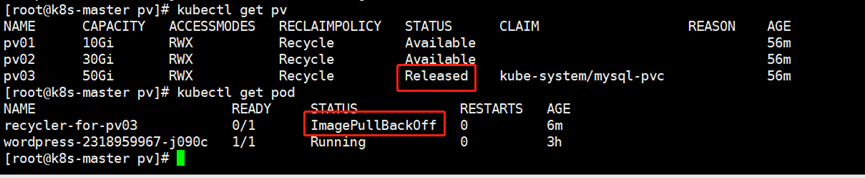
1.删除资源
##删除PVC
kubectl delete pvc tomcat-mysql-pvc -n tomcat
发现pv的状态变成了released状态,同时发现有一个pod状态不正常
2.解决"ErrImagePull"问题
(1)在线编辑"pv-recycler"的POD资源
kubectl edit po recycler-for-pv03
(2)修改镜像地址为国内的阿里云源
image: registry.aliyuncs.com/google_containers/busybox
这是k8s内置的只能在线编辑,pv的回收又依赖这个pod3.回收pv资源
此时发现pv的状态又变成了failed状态,是因为deployment资源的mysql进程依然占用着pv下的文件,导致数据无法删除。可以手动删除
当然,如果先删除deployment资源,再删除pvc就不会出现failed情况
7.PVC的标签选择器
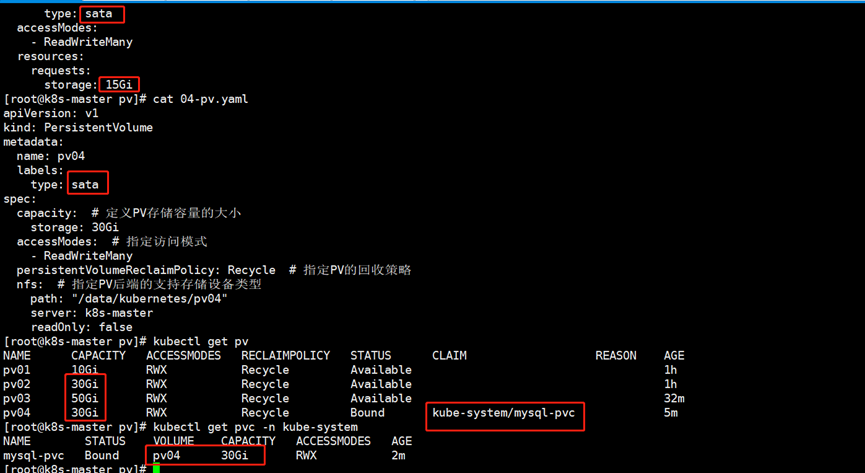
1.创建PV
[root@k8s-master pv]# cat 04-pv.yaml
apiVersion: v1
kind: PersistentVolume
metadata:
name: pv04
labels:
type: sata
spec:
capacity: # 定义PV存储容量的大小
storage: 30Gi
accessModes: # 指定访问模式
- ReadWriteMany
persistentVolumeReclaimPolicy: Recycle # 指定PV的回收策略
nfs: # 指定PV后端的支持存储设备类型
path: "/data/kubernetes/pv04"
server: k8s-master
readOnly: false
[root@k8s-master pv]# kubectl apply -f 04-pv.yaml
2.创建PVC
[root@k8s-master pv]# cat 03-pvc.yaml
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: mysql-pvc
namespace: kube-system
spec:
selector: ###指定标签选择器
matchLabels:
type: sata
accessModes:
- ReadWriteMany
resources:
requests:
storage: 15Gi
[root@k8s-master pv]# kubectl apply -f 03-pvc.yaml
如下图所示,当我们成功创建了pvc资源时,其存储要求是15GB,尽管pv02和pv04均满足15GB的存储要求,但始终会被调度到pv04,这正是由于标签选择器的存在
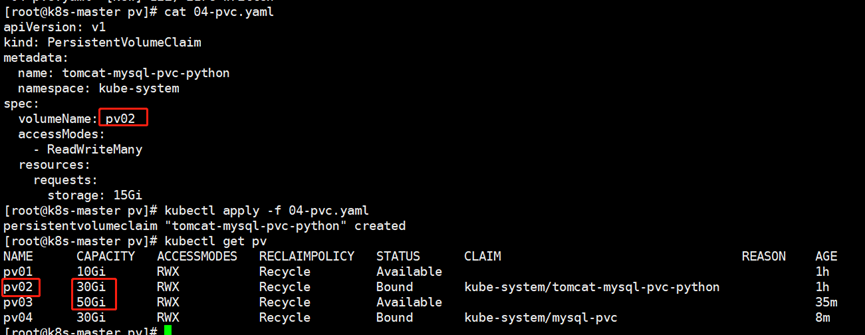
3.基于pv名称选择
[root@k8s-master pv]# cat 04-pvc.yaml
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: tomcat-mysql-pvc-python
namespace: kube-system
spec:
volumeName: pv02 ###指定pv的名称
accessModes:
- ReadWriteMany
resources:
requests:
storage: 15Gi
[root@k8s-master pv]# kubectl apply -f 04-pvc.yaml
可以看到虽然pv02和pv03都满足要求,但是依然选择了pv02,这是因为指定了名称
未经允许不得转载:孙某某的运维之路 » 5.k8s的数据持久化存储

评论已关闭