6.k8s使用ceph分布式集群存储
孙富阳, 江湖人称没人称。多年互联网运维工作经验,曾负责过孙布斯大规模集群架构自动化运维管理工作。擅长Web集群架构与自动化运维,曾负责国内某大型博客网站运维工作。
1.Ceph分布式存储系统概述
Ceph是一个对象(object)式存储系统,它把每一个待管理的数据流(例如一个文件)切分为一到多个固定大小的对象数据,并以其为原子单元完成数据存取。
对象数据的底层存储服务时由多个主机(host)组成的存储系统,该集群也被称之为RADOS(Reliable Automatic Distributed Object Store)存储集群,即可靠,自动化,分布式对象存储系统。
librados是RADOS存储集群的API,它支持C,C++,Java,Python,Ruby和PHP等编程语言。
由于直接基于librados这个API才能使用Ceph集群的话对使用者是有一定门槛的。当然,这一点Ceph官方也意识到了,于是他们还对Ceph做出了三个抽象资源,分别为RADOSGW,RBD,CEPHFS等。
RadosGw,RBD和CephFS都是RADOS存储服务的客户端,他们把RADOS的存储服务接口(librados)分别从不同的角度做了进一步抽象,因而各自适用不同的应用场景,如下所示:
RadosGw:
它是一个更抽象的能够跨互联网的云存储对象,它是基于RESTful风格提供的服务。每一个文件都是一个对象,而文件大小是各不相同的。
他和Ceph集群的内部的对象(object,它是固定大小的存储块,只能在Ceph集群内部使用,基于RPC协议工作的)并不相同。
值得注意的是,RadosGw依赖于librados哟,访问他可以基于http/https协议来进行访问。
RBD:
将ceph集群提供的存储空间模拟成一个又一个独立的块设备。每个块设备都相当于一个传统磁(硬)盘一样,你可以对它做格式化,分区,挂载等处理。
值得注意的是,RBD依赖于librados哟,访问需要Linux内核支持librdb相关模块哟。
CephFS:
很明显,这是Ceph集群的文件系统,我们可以很轻松的像NFS那样使用,但它的性能瓶颈相比NFS来说是很难遇到的。
值得注意的是,CephFS并不依赖于librados哟,它和librados是两个不同的组件。但该组件使用的热度相比RadosGw和RBD要低。
推荐阅读:
查看ceph的官方文档: https://docs.ceph.com/en/latest/
中文社区文档: http://docs.ceph.org.cn
温馨提示:
(1)CRUSH算法是Ceph内部数据对象存储路由的算法。它没有中心节点,即没有元数据中心服务器。
(2)无论使用librados,RadosGw,RBD,CephFS哪个客户端来存储数据,最终的数据都会被写入到Rados Cluster,值得注意的是这些客户端和Rados Cluster之间应该有多个存储池(pool),每个客户端类型都有自己的存储池资源。
2.Ceph部署实战
1.准备3台节点
三台节点每台2块硬盘,并添加hosts解析
[root@ceph01 ~]# cat /etc/hosts
127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4
::1 localhost localhost.localdomain localhost6 localhost6.localdomain6
10.0.0.14 ceph01
10.0.0.15 ceph02
10.0.0.16 ceph03
[root@ceph01 ~]# scp -rp /etc/hosts 10.0.0.15:/etc/hosts
[root@ceph01 ~]# scp -rp /etc/hosts 10.0.0.16:/etc/hosts
2.配置免密登录(后续ceph-deploy工具依赖免密登录)
[root@ceph01 ~]# ssh-keygen -t rsa -f ~/.ssh/id_rsa -P '' -q
[root@ceph01 ~]# ssh-copy-id ceph01
[root@ceph01 ~]# scp -rp .ssh/ ceph02:/root/
[root@ceph01 ~]# scp -rp .ssh/ ceph03:/root/
3."ceph01"节点安装"ceph-deploy"工具,用于后期部署ceph集群
###准备国内的软件源(含基础镜像软件源和epel源)
[root@ceph01 ~]# curl -o /etc/yum.repos.d/CentOS-Base.repo http://mirrors.aliyun.com/repo/Centos-7.repo
[root@ceph01 ~]# curl -o /etc/yum.repos.d/epel.repo http://mirrors.aliyun.com/repo/epel-7.repo
###配置ceph软件源
[root@ceph01 ~]# cat /etc/yum.repos.d/ceph.repo
[ceph]
name=ceph 2021
baseurl=https://mirrors.tuna.tsinghua.edu.cn/ceph/rpm-octopus/el7/x86_64/
gpgcheck=0
enable=1
[ceph-tools]
name=ceph tools
baseurl=https://mirrors.tuna.tsinghua.edu.cn/ceph/rpm-octopus/el7/noarch/
gpgcheck=0
enable=1
###ceph01节点安装"ceph-deploy"工具,用于后期部署ceph集群
[root@ceph01 ~]# sed -ri 's#(keepcache=)0#\11#' /etc/yum.conf
[root@ceph01 ~]# yum makecache
[root@ceph01 ~]# yum -y install ceph-deploy
###将rpm软件源推送到其它节点
[root@ceph01 ~]# scp /etc/yum.repos.d/*.repo ceph02:/etc/yum.repos.d/
[root@ceph01 ~]# scp /etc/yum.repos.d/*.repo ceph03:/etc/yum.repos.d/
4.ceph环境准备
###ceph01节点安装ceph环境
[root@ceph01 ~]# yum -y install ceph ceph-mon ceph-mgr ceph-radosgw ceph-mds ceph-osd
相关软件包功能说明如下:
ceph:ceph通用模块软件包。
ceph-mon: ceph数据的监控和分配数据存储,其中mon是monitor的简写。
ceph-mgr:管理集群状态的组件。其中mgr是manager的简写。基于该组件我们可以让zabbix来监控ceph集群哟。
ceph-radosgw:对象存储网关,多用于ceph对象存储相关模块软件包。
ceph-mds: ceph的文件存储相关模块软件包,即"metadata server"
ceph-osd:ceph的块存储相关模块软件包
###将软件打包到本地并推送到其它节点
[root@ceph01 ~]# mkdir ceph-rpm
[root@ceph01 ~]# find /var/cache/yum/ -type f -name "*.rpm" | xargs mv -t ceph-rpm/
[root@ceph01 ~]# tar zcf ceph.tar.gz ceph-rpm
[root@ceph01 ~]# scp ceph.tar.gz ceph02:~
[root@ceph01 ~]# scp ceph.tar.gz ceph03:~
###其它节点安装ceph环境
[root@echp02 ~]# tar xf ceph.tar.gz
[root@echp02 ~]# cd ceph-rpm/
[root@echp02 ceph-rpm]# yum localinstall *.rpm -y
5.初始化ceph的配置文件
###自定义创建ceph的配置文件目录
[root@ceph01 ~]# mkdir ceph-cluster
[root@ceph01 ~]# cd ceph-cluster
###初始化ceph的配置文件
[root@ceph01 ceph-cluster]# ceph-deploy new --public-network 10.0.0.0/24 ceph01 ceph02 ceph03
发现报错了
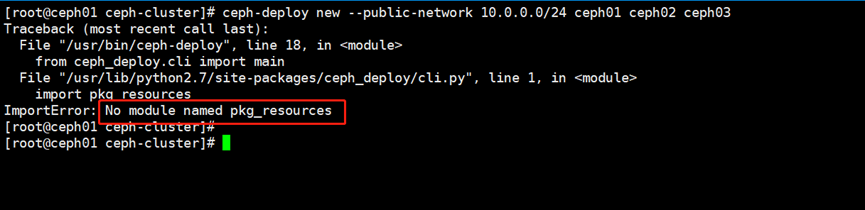
##解决办法
[root@ceph01 ceph-cluster]# yum -y install gcc python-setuptools python-devel
温馨提示:
可以使用"--cluster-network"参数创建集群内部的网络,其通常是集群内部通信的网段。而"--public-network"参数用于创建集群外部的网络,通常是客户端访问的网络,生产环境中建议分开配置。我这里就没有使用"--cluster-network"参数,若不是用则默认仅使用同一套网络6.安装ceph-monitor并启动ceph-mon
[root@ceph01 ceph-cluster]# ceph-deploy mon create-initial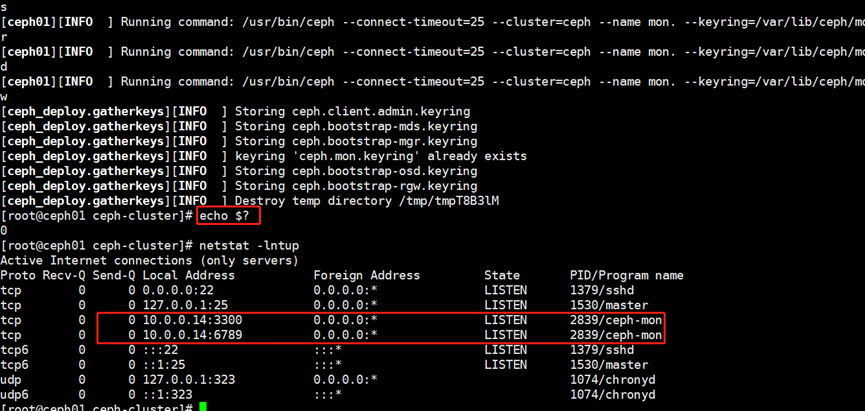
7.将配置和client.admin密钥推送到指定的远程主机以便于管理集群
admin用户是ceph集群自带的用户,将用户推送到节点即可
[root@ceph01 ceph-cluster]# ceph-deploy admin ceph01 ceph02 ceph03
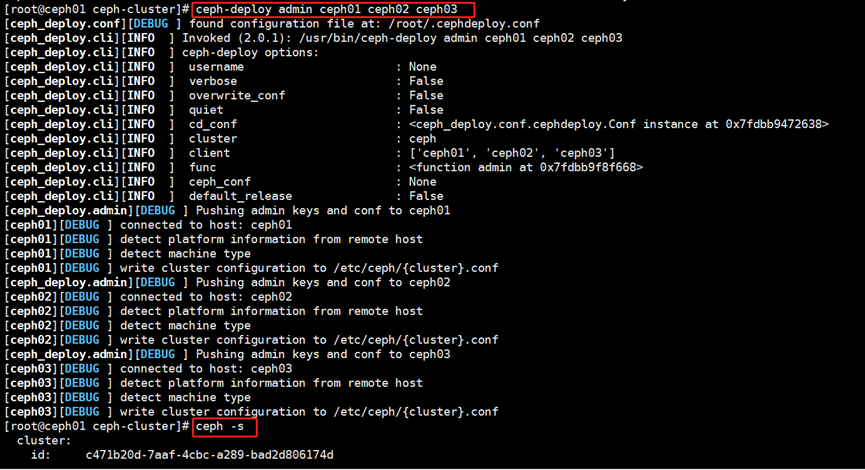
8.安装并启动ceph-mgr组件
[root@ceph01 ceph-cluster]# ceph-deploy mgr create ceph01 ceph02 ceph03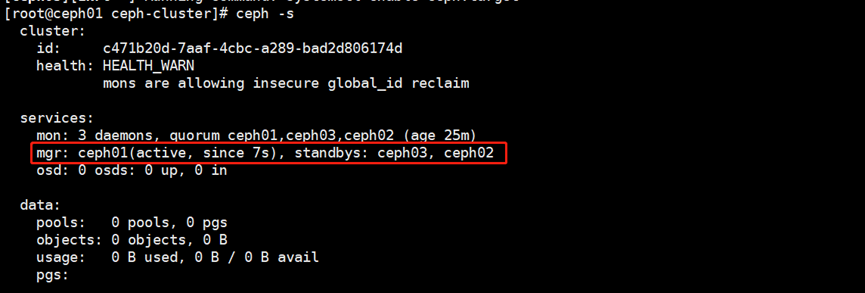
9.安装OSD设备
[root@ceph01 ceph-cluster]# ceph-deploy osd create ceph01 --data /dev/sdb
[root@ceph01 ceph-cluster]# ceph-deploy osd create ceph02 --data /dev/sdb
[root@ceph01 ceph-cluster]# ceph-deploy osd create ceph03 --data /dev/sdb
创建OSD是要注意的相关参数说明:
--data DATA:指定逻辑卷或者设备的绝对路径。
--journal JOURNAL:指定逻辑卷或者GPT分区的分区路径。生产环境强烈指定该参数,并推荐使用SSD设备。因为ceph需要先预写日志而后才会真实写入数据,从而达到防止数据丢失的目的。若不指定该参数,则日志会写入"--data"指定的路径哟。从而降低性能。对于一个4T的数据盘,其日志并不会占据特别多的空间,通常情况下分配50G足以,当然,LVM是支持动态扩容的
综上所述—journal指定日志盘,如果不指定的话,日志盘和数据盘都在—data指定,这样会拉低ceph的性能
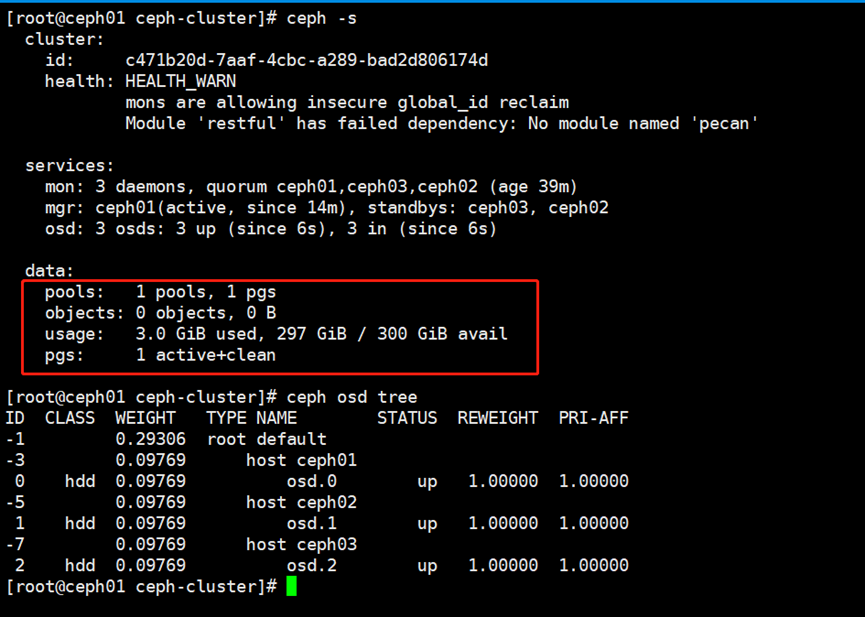
3.Ceph块存储的使用
1.ceph的存储池基本管理
###查看现有的所有资源池
[root@ceph01 ~]# ceph osd pool ls
###创建资源池
[root@ceph01 ~]# ceph osd pool create sfy-test 128 128
这个128是pg的个数,数值越大,数据分布越分散,最大值251,并且只能是2的倍数,设置128在任何场景下都够用了
###查看存储池的参数信息(这个值可能会不断的变化~尤其是在重命名后!)
[root@ceph01 ~]# ceph osd pool get sfy-test pg_num
###资源池的重命名
ceph osd pool rename sfy-test sfy01
###查看资源池的状态
[root@ceph01 ~]# ceph osd pool stats
###删除资源池(需要开启删除的功能,否则会报错哟~而且池的名字得写2次!)
[root@ceph01 ~]# ceph osd pool rm sfy-test sfy-test --yes-i-really-really-mean-it
2.rbd的块设备(镜像,image)管理
###查看sfy-test资源池下的rbd的块(镜像,image)设备
[root@ceph01 ~]# rbd list -p sfy-test
rbd ls -p sfy-test --long --format json --pretty-format #指定输出的样式
###创建rbd的块设备:(下面写法等效哟)
rbd create --size 1024 --pool sfy-test test.img # 不指定单位默认为M
rbd create --size 1024 sfy-test/test.img
rbd create -s 2G -p sfy-test test.img # 也可以指定单位,比如G
###修改镜像设备的名称
[root@ceph02 ~]# rbd rename -p sfy-test test.img test
###查看镜像的状态
[root@ceph02 ~]# rbd status -p sfy-test test
###移除镜像文件
[root@ceph02 ~]# rbd remove -p sfy-test test
###查看rbd的详细信息
[root@ceph02 ~]# rbd info -p sfy-test test.img
3.挂载rbd的块设备
###添加映射关系
[root@ceph01 ~]# rbd map sfy-test/test.img
但是提示内核不支持,需要按照提示禁用一些核心特性,这是因为centos7的内核版本太老了

###禁用不支持的核心特性并重新添加映射关系
[root@ceph01 ~]# rbd feature disable sfy-test/test.img object-map fast-diff deep-flatten
###格式化磁盘并挂载磁盘
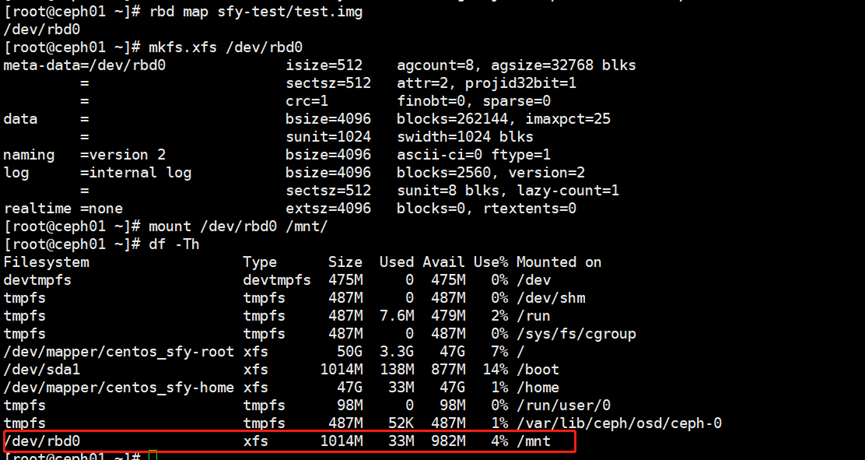
[root@ceph01 ~]# mkfs.xfs /dev/rbd0
[root@ceph01 ~]# mount /dev/rbd0 /mnt/
如下图可以看到已经挂载成功了
4.使用rbd块设备
[root@ceph01 ~]# cd /mnt/
###查看块设备信息
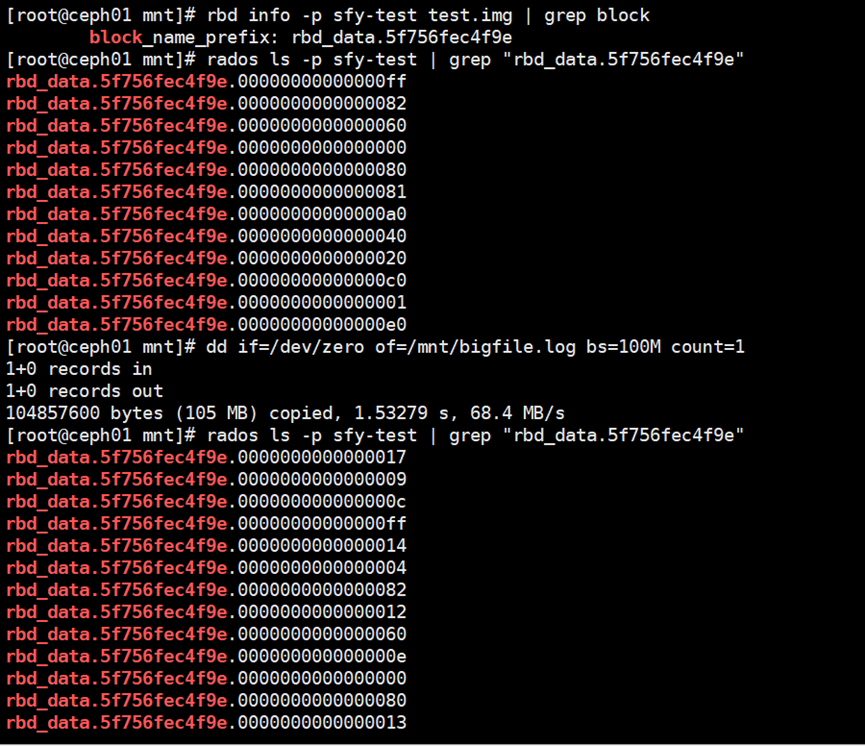
[root@ceph01 mnt]# rbd info -p sfy-test test.img | grep block
###查看存储的object对象
[root@ceph01 mnt]# rados ls -p sfy-test | grep "rbd_data.5f756fec4f9e"
###创建测试文件
[root@ceph01 mnt]# dd if=/dev/zero of=/mnt/bigfile.log bs=100M count=1
如下图,写入的数据被分成了多个对象
###ceph02节点挂载设备使用
[root@ceph02 ~]# rbd map sfy-test/test.img
[root@ceph02 ~]# mount /dev/rbd
[root@ceph02 ~]# cd /mnt/
###此时再在ceph02上创建数据
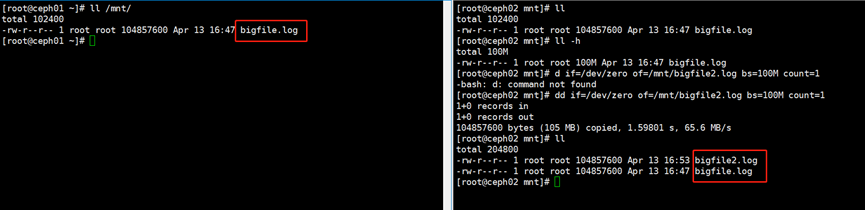
[root@ceph02 mnt]# dd if=/dev/zero of=/mnt/bigfile2.log bs=100M count=1
如下图,一个rbd集群的同一个image设备可以挂载到不同的节点上;但同一个image设备在不同的节点上无法实现的数据的同步
5.扩容rbd块设备
##自动扩缩容磁盘大小:(扩容正常,缩容可能会导致设备不可用!需要进一步调研,生产环境要充分测试方能使用!)
rbd resize --size 4096 sfy-test/test.img
rbd resize -s 1G sfy-test/test.img --allow-shrink # 慎用,可能会导致设备不可用!
自动扩展XFS文件系统到最大的可用大小:xfs_growfs /mnt
4.ceph增加osd节点
1.添加osd的准备条件
为什么要添加OSD?
因为随着我们对ceph集群的使用,资源可能会被消耗殆尽,这个时候就得想法扩容集群资源,对于ceph存储资源的扩容,我们只需要添加相应的OSD节点即可。
添加OSD的准备条件:
我们需要单独添加一个新的节点并为其多添加一块磁盘
2.新增节点配置解析记录并配置免密码登录
cat /etc/hosts
127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4
::1 localhost localhost.localdomain localhost6 localhost6.localdomain6
10.0.0.14 ceph01
10.0.0.15 ceph02
10.0.0.16 ceph03
10.0.0.17 ceph04
[root@ceph01 ~]# scp -rp .ssh/ ceph04:/root/
3.新增节点部署ceph软件包
###配置案例的软件源
curl -o /etc/yum.repos.d/epel.repo http://mirrors.aliyun.com/repo/epel-7.repo
###将ceph01的yum仓库配置文件拷贝到ceph04
scp /etc/yum.repos.d/ceph.repo ceph204:/etc/yum.repos.d/
###ceph04节点只需安装osd相关的组件即可,因为它并不作为管理节点,而是作为存储节点哟。
yum -y install ceph-osd
systemctl stop firewalld && systemctl disable firewalld # 禁用防火墙功能。
###在ceph节点安装以下的软件包,否则无法添加节点。
python36-PyYAML-3.13-1.el7.x86_64.rpm
python36-six-1.14.0-3.el7.noarch.rpm
# python-six-1.9.0-2.el7.noarch.rpm # 该模块可以不选择安装哈!
4.在ceph01管理节点添加新增节点的OSD
cd /root/ceph/cluster
ceph-deploy osd create ceph04 --data /dev/sdb
ps:当我们添加OSD时会自动进行数据的负载均衡,因此建议大家如果真需要扩容时可以考虑在业务的低谷期进行
5.使用ceph对接kubernetes
1.在K8S集群中安装ceph的基础包环境
###将ceph软件源,epel的软件源拷贝到k8s的master节点
[root@ceph01 yum.repos.d]# scp ceph.repo epel.repo 10.0.0.12:`pwd`
###安装ceph的基础包
[root@k8s-node-1 ~]# yum -y install ceph-common
[root@k8s-node-2 ~]# yum -y install ceph-common
参考连接:
https://kubernetes.io/docs/concepts/storage/volumes/#rbd
https://github.com/kubernetes/examples/tree/master/volumes/rbd
2.创建sercet资源使用Ceph身份验证密钥
###如果提供了Ceph身份验证密钥,则该密钥应首先进行base64编码,然后将编码后的字符串放入密钥yaml中
[root@ceph01 yum.repos.d]# grep key /etc/ceph/ceph.client.admin.keyring |awk '{printf "%s", $NF}'|base64
QVFDZmJGWmk1RHV2SWhBQUJlcXh4b2RpdXBtSW9RRFNFeEtCaWc9PQ==
###创建Secret资源,注意替换key的值,要和ceph集群的key保持一致哟,上一步我已经取出来了
[root@k8s-master ceph-chijiuhua]# cat ceph-secret.yaml
apiVersion: v1
kind: Secret
metadata:
name: ceph-secret
type: "kubernetes.io/rbd"
data:
key: QVFDZmJGWmk1RHV2SWhBQUJlcXh4b2RpdXBtSW9RRFNFeEtCaWc9PQo=
###在K8S集群中创建Secret资源,以便于后期Pod使用该资源
[root@k8s-master ceph-chijiuhua]# kubectl apply -f ceph-secret.yaml
参考连接:
https://github.com/kubernetes/examples/blob/master/volumes/rbd/secret/ceph-secret.yaml
3.创建k8s专用存储池及mysql专用块设备
###创建存储池
[root@ceph01 yum.repos.d]# ceph osd pool create k8s 128 128
###创建块设备
值得注意的是,我们可以指定该镜像的特性,否则由于内核版本过低而无法挂载哟
[root@ceph01 yum.repos.d]# rbd create -p k8s --size 1024 --image-feature layering k8s-mysql
4.创建yaml文件对接ceph块设备
[root@k8s-master ceph-chijiuhua]# cat deploy-pvc.yaml
apiVersion: extensions/v1beta1
kind: Deployment
metadata:
name: mysql
spec:
replicas: 1
template:
metadata:
labels:
app: mysql
spec:
volumes:
- name: rbdpd
rbd: ###指定持久化类型为rbd
monitors: ###指定mon节点ip
- '10.0.0.14:6789'
- '10.0.0.15:6789'
- '10.0.0.16:6789'
pool: k8s ###指定存储池名字,这个名字必须存在
image: k8s-mysql ###指定块设备,这个也必须存在
fsType: xfs ###指定文件系统类型
readOnly: false ###是否只读
user: admin ###ceph集群管理用户
secretRef: ###指定secret资源名称
name: ceph-secret ###需要使用的secret资源名字
# imageformat: "2" 格式
# imagefeatures: "layering" 指定块设备特性
containers:
- name: mysql
volumeMounts:
- name: rbdpd # 注意哈,该名称必须在上面的"volumes"的name字段中存在哟~
mountPath: /var/lib/mysql # 指定挂载到容器的位置
image: k8s-master:5000/mysql:5.7
ports:
- containerPort: 3306
env:
- name: MYSQL_ROOT_PASSWORD
value: somewordpress
- name: MYSQL_DATABASE
value: wordpress
- name: MYSQL_USER
value: wordpress
- name: MYSQL_PASSWORD
value: wordpress
---
apiVersion: v1
kind: Service #简称svc
metadata:
name: musql-svc
namespace: kube-system
spec:
clusterIP: 10.254.86.101
type: ClusterIP
ports:
- port: 3306
targetPort: 3306 #pod port
selector:
app: mysql
---
apiVersion: extensions/v1beta1
kind: Deployment
metadata:
name: wordpress
spec:
replicas: 1
template:
metadata:
labels:
app: wordpress
spec:
containers:
- name: wordpress
image: k8s-master:5000/wordpress:latest
ports:
- containerPort: 80
env:
- name: WORDPRESS_DB_HOST
value: musql-svc.kube-system.svc.cluster.local
- name: WORDPRESS_DB_USER
value: wordpress
- name: WORDPRESS_DB_PASSWORD
value: wordpress
---
apiVersion: v1
kind: Service #简称svc
metadata:
name: wordpress-svc
spec:
type: NodePort
ports:
- port: 80
nodePort: 31001
targetPort: 80 #pod port
selector:
app: wordpress
[root@k8s-master ceph-chijiuhua]# kubectl apply -f deploy-pvc.yaml

未经允许不得转载:孙某某的运维之路 » 6.k8s使用ceph分布式集群存储

评论已关闭