1.Elasticsearch快速入门
孙富阳, 江湖人称没人称。多年互联网运维工作经验,曾负责过孙布斯大规模集群架构自动化运维管理工作。擅长Web集群架构与自动化运维,曾负责国内某大型博客网站运维工作。
1.Elasticsearch介绍
1.什么是Lucene
Lucene是一个高性能的java搜索引擎库,操作非常繁琐,需要具备java开发经验。 Elasticsearch是基于Lucene之上包装一层外壳,屏蔽了Lucene的复杂操作,即使不会java语言也可以快速上手。2.什么是全文检索和倒排索引
建议参考下方链接:
https://www.cnblogs.com/zhaoshaopeng/p/12876111.html
什么是索引
索引就好比书的目录,如果我们想快速查看某个章节,只需要找到目录里相应章节对应的页数即可。
通过目录找到章节,通过章节找到页码这个过程就是索引的过程。
索引的目的就是加快数据搜索的效率
什么是全文检索
先建立索引,再对索引进行搜索的过程就叫全文检索(Full-text Search)。
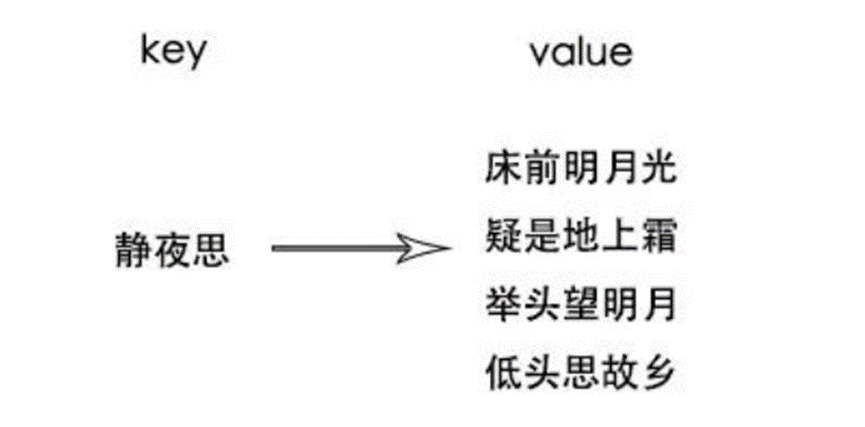
例如让你背一首诗,诗的名字叫静夜思,那么静夜思就是索引。
以下图片就是一个全文索引,也叫正向索引
什么是倒排索引
索引是根据章节找到页数,但是如果我并不知道我要找的内容属于哪个章节,比如我只知道一个关键词,但是不知道这个关键词属于哪个章节。
大家可以想一下,我们平时利用搜索引擎搜索的时候是不是也是这种场景呢? 比如我们想知道一个电影的名字,但是记不起来具体的名字,只知道部分关键词或者剧情的内容,那这种情景背后如何用技术解决呢?
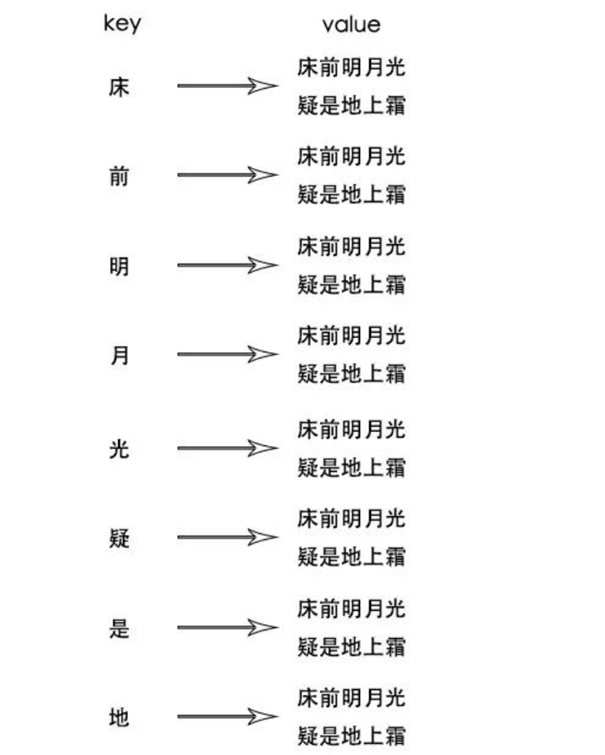
这时候就不得不提到倒排索引了
以下就是一个倒排索引的例子
但是这样数据量就太大了,还可以这样压缩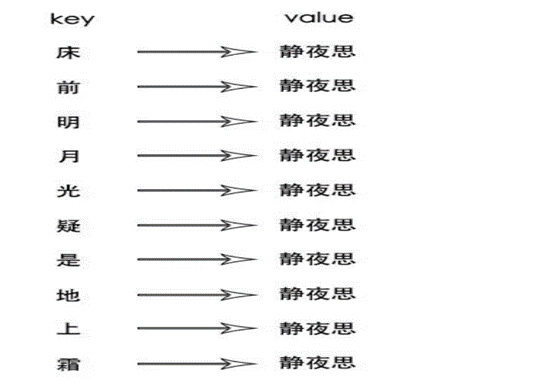
2.Elasticsearch安装
1.关闭防火墙和Selinux并下载软件包
systemctl stop firewalld.service
setenforce 0
mkdir /data/soft -p
cd /data/soft/
wget https://artifacts.elastic.co/downloads/elasticsearch/elasticsearch-7.9.1-x86_64.rpm
2.安装jdk并在安装ES后启动检查
对于Elasticsearch7.0之后的版本不需要再独立的安装JDK了,软件包里已经自带了最新的JDK,所以直接启动即可。
yum localinstall -y elasticsearch-7.9.1-x86_64.rpm
systemctl daemon-reload
systemctl enable elasticsearch.service
systemctl start elasticsearch.service
netstat -lntup|grep 9200
curl 127.0.0.1:9200
3.Elasticsearch自定义配置
1.查看ES有哪些配置文件
[root@node01 ~]# rpm -qc elasticsearch
/etc/elasticsearch/elasticsearch.yml #主配置文件
/etc/elasticsearch/jvm.options #JVM配置文件
/etc/init.d/elasticsearch #init启动脚本
/etc/sysconfig/elasticsearch #环境变量文件
/usr/lib/sysctl.d/elasticsearch.conf #内核参数文件
/usr/lib/systemd/system/elasticsearch.service#systemd启动文件
2.编辑配置文件
[root@node01 ~]# grep -E "^[a-Z]" /etc/elasticsearch/elasticsearch.yml
node.name: es-01#####节点名称
path.data: /var/lib/elasticsearch####数据目录
path.logs: /var/log/elasticsearch####日志目录
bootstrap.memory_lock: true####锁内存,不使用swap分区
network.host: 0.0.0.0###监听的网络地址
http.port: 9200####监听的端口
discovery.seed_hosts: ["10.0.0.80"]####自动发现的主机
cluster.initial_master_nodes: ["10.0.0.80"]####参与master选举的节点
3.重启服务并解决内存锁定失败问题
systemctl restart elasticsearch.service
重启发现提示内存锁定失败,需要根据官网帮助手册修改启动文件
https://www.elastic.co/guide/en/elasticsearch/reference/current/setting-system-settings.html#systemd
systemctl edit elasticsearch
[Service]
LimitMEMLOCK=infinity
systemctl daemon-reload
systemctl restart elasticsearch.service
4.Elasticsearch插件安装
1.elasticsearch-head介绍
官方地址: https://github.com/mobz/elasticsearch-head
elasticsearch-head是一款用来管理Elasticsearch集群的第三方插件工具。
elasticsearch-Head插件在5.0版本之前可以直接以插件的形式直接安装,但是5.0以后安装方式发生了改变,需要nodejs环境支持,或者直接 使用别人封装好的docker镜像,更推荐的是谷歌浏览器的插件
2.elasticsearch-head的三种安装方式
1.docker安装elasticsearch-head
docker run -p 9100:9100 mobz/elasticsearch-head:7
2.npm安装elasticsearch-head
cd /opt/
wget https://nodejs.org/dist/v12.13.0/node-v12.13.0-linux-x64.tar.xz
tar xf node-v12.13.0-linux-x64.tar.xz
mv node-v12.13.0-linux-x64 node
echo 'export PATH=$PATH:/opt/node/bin' >> /etc/profile
source /etc/profile
npm -v
node -v
git clone git://github.com/mobz/elasticsearch-head.git
cd elasticsearch-head
npm install -g cnpm --registry=https://registry.npm.taobao.org
cnpm install
cnpm run start
修改Elasticsearch配置文件,添加如下参数并重启
http.cors.enabled: true
http.cors.allow-origin: "*"
3.es-head谷歌浏览器插件安装
更多工具-->拓展程序-->开发者模式-->选择解压缩后的插件目录
测试连接elasticsearch
5.安装kibana连接es数据库
1.安装kibana修改配置文件
##安装
wget https://artifacts.elastic.co/downloads/kibana/kibana-7.14.0-x86_64.rpm
yum localinstall -y kibana-7.14.0-x86_64.rpm
##配置文件
[root@node01 ~]# grep -E "^[a-Z]" /etc/kibana/kibana.yml
server.port: 5601###服务端口
server.host: "0.0.0.0"###监听的地址
elasticsearch.hosts: ["http://10.0.0.80:9200"]###es地址
kibana.index: ".kibana"##索引名
i18n.locale: "zh-CN"###中文汉化
2.启动kibana并登录检查测试
systemctl start kibana
http://10.0.0.51:5601/
6.Elasticsearch插入命令
1.Elasticsearch数据格式
和MySQL对比:
MySQL Elasticsearch
库 索引 index
表 类型 _doc
字段 json数据的key
值 json数据的value
行 文档 doc
2.使用自定义的ID
curl命令操作
[root@node01 ~]# curl -XPUT 'http://10.0.0.80:9200/linux/_doc/1' -H 'Content-Type: application/json' -d '
{
"name": "zhang",
"age": "29"
}'
kibana界面操作:
PUT linux/_doc/1
{
"name": "zhang",
"age": "29"
}
###注意,如果web页面直接使用如下命令,将创建随机id
PUT linux/_doc/
{
"name": "zhang",
"age": "29"
}
3.和mysql数据对应关系
mysql
id name age address job
1 zhang 27 BJ it
2 ya 22 SZ it
POST linux/_doc/
{
"id": "1",
"name": "zhang",
"age": "29",
"address": "BJ",
"job": "it"
}
POST linux/_doc/
{
"id": "2",
"name": "ya",
"age": "22",
"address": "SZ",
"job": "it"
}
7.kibana页面的Elasticsearch查询命令
1.创建测试语句
POST linux/_doc/1
{
"name":"www",
"age":"14"
}
2.简单查询
GET linux/_search/3.条件查询
#term查询 一般根据 数据文档中 某一个键值的内容进行查询
GET sunfuyang/_search
{
"query": {
"term": {
"name": {
"value": "wang"
}
}
}
}
4.多条件查询
GET linux/_search
{
"query": {
"bool": {
"must": [
{
"term": {
"address.keyword": "BJ"
}
},
{
"term": {
"job.keyword": "dev"
}
},
{
"range": {
"age.keyword": {
"gt": "24",
"lt": "31"
}
}
}
]
}
}
}
8.kibana页面的Elasticsearch更新命令
1.自定义ID的内容更新
PUT linux/_doc/1
{
"name":"www",
"age":"14"
}
2.随机ID更新
创建测试数据
PUT linux/_doc/1
{
"name": "zhang",
"age": "30",
"job": "it",
"id": 2
}
先根据自定义的Id字段查出数据的随机ID
GET linux/_search/
{
"query": {
"term": {
"id": {
"value": "2"
}
}
}
}
取到随机ID后使用put更改数据
9.kibana页面的Elasticsearch删除命令
DELETE linux/_doc/1未经允许不得转载:孙某某的运维之路 » 1.Elasticsearch快速入门

评论已关闭