4.Logstash日志处理快速入门
孙富阳, 江湖人称没人称。多年互联网运维工作经验,曾负责过孙布斯大规模集群架构自动化运维管理工作。擅长Web集群架构与自动化运维,曾负责国内某大型博客网站运维工作。
1.logstash介绍
1.为什么需要logstash
对于部分生产上的日志无法像Nginx那样,可以直接将输出的日志转为json格式,但是可以借助logstash来将我们的“非结构化数据”,转为“结构化数据”;
而且logstash的数据是均匀的打到es数据库的,可以减轻es的压力。
2.什么是logstash
Logstash是开源的数据处理管道,能够同时从多个源采集数据,转换数据,然后输出数据。3.logstash架构介绍
Logstash的基础架构类似于pipeline流水线
Input:数据采集(常用插件:stdin、file、kafka、beat、http)
Filter:数据解析转换(常用插件:grok、date、geoip、mutate、useragent)
Output:数据输出(常用插件:elasticsearch)
2.logstash input插件
1.input插件介绍
Input插件用于指定输入源,一个pipeline可以有多个input插件,我们主要围绕下面介个input插件进行介绍
Stdin
File
Beat
Kafka
2.stdin插件
从标准输入读取数据,从标准输出中输出内容;
###安装java
[root@es-node3 ~]# yum -y install java
###安装logstash
[root@es-node3 ~]# yum localinstall logstash-7.9.3.rpm -y
###编辑配置文件
[root@es-node3 ~]# cat /etc/logstash/conf.d/stdin_Logstash.conf
input {
stdin { ###插件类型为stdin
type => "stdin" ###自定义一个类型的名字
tags => "stdin_type" ###自定义一个tags
}
}
output {
stdout { ###输出的插件类型
codec => "rubydebug"
}
}
###启动logstash
[root@es-node3 ~]# /usr/share/logstash/bin/logstash -f /etc/logstash/conf.d/stdin_Logstash.conf
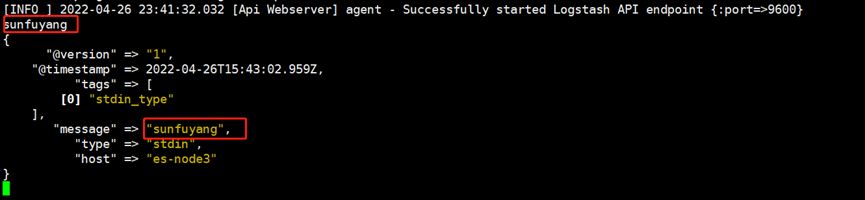
等待约30秒后启动成功,直接在当前终端输入sunfuyang可以看到输出结果,比filebeat简洁的多。
3.file插件
从file文件中读取数据,然后输入至标准输入;
###编辑配置文件
[root@es-node3 ~]# cat /etc/logstash/conf.d/file_Logstash.conf
input {
file {
path => "/var/log/sunfuyang.log"
type => "syslog"
exclude => "*.gz" ###排除的文件
start_position => "beginning" ###第一次从头读取文件 beginning or end
stat_interval => "3" ###定时检查文件是否更新,默认1s
}
}
output {
stdout {
codec => "rubydebug"
}
}
###启动logstash
[root@es-node3 ~]# /usr/share/logstash/bin/logstash -f /etc/logstash/conf.d/file_Logstash.conf
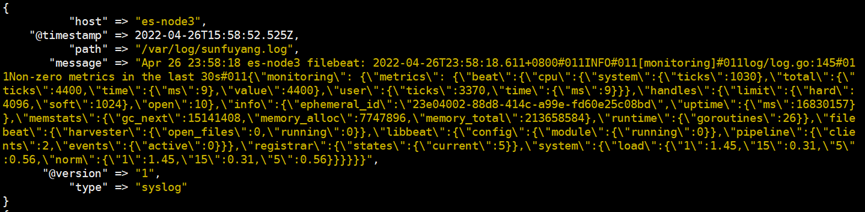
可以看到很多下图所示的输出
4.beats插件
从filebeat中读取数据,然后输入至标准输入;
前提是filebeat输出到logstash。
input {
beats {
port => 5044
}
}
output {
stdout {
codec => "rubydebug"
}
}
5.kafka插件
从kafka中读取数据,然后输入至标准输出;
[root@es-node3 ~]# cat /etc/logstash/conf.d/kafka_Logstash.conf
input {
kafka {
zk_connect => "kafka1:2181,kafka2:2181,kafka3:2181"
group_id => "logstash"
topic_id => "apache_logs"
consumer_threads => 16
}
}
output {
stdout {
codec => "rubydebug"
}
}
3.logstash filter插件
1.filter插件介绍
数据从源传输到存储的过程中,logstash的filter过滤器能够解析各个事件,识别已命名的字段结构,并将它们转换成通用格式,以便更轻松更快速的分析和实现商业价值;
利用grok从非结构化数据中派生出结构化数据
利用geoip从ip地址分析出地理坐标
利用useragent从请求中分析操作系统、设备类型
2.Grok插件
Grok其实是带有名字的正则表达式集合。Grok内置了很多pattern可以直接使用,如下配置是一个将Nginx日志格式化为json格式的配置示例
[root@es-node3 ~]# cat /etc/logstash/conf.d/grok_filter.conf
input {
http {
port => 7474
}
}
filter {
grok {
match => {
"message" => "%{COMBINEDAPACHELOG}"
}
}
}
output {
stdout {
codec => rubydebug
}
}
3.Geoip插件
Geoip插件可以根据IP地址提供的对应地域信息,比如经纬度、城市名等、方便进行地理数据分析;
如下是一个配置示例
[root@es-node3 ~]# cat /etc/logstash/conf.d/grok_filter.conf
input {
http {
port => 7474
}
}
filter {
grok {
match => {
"message" => "%{COMBINEDAPACHELOG}"
}
}
geoip {
source => "clientip" ###clientip需要在grok插件中有这个字段
}
}
output {
stdout {
codec => rubydebug
}
}
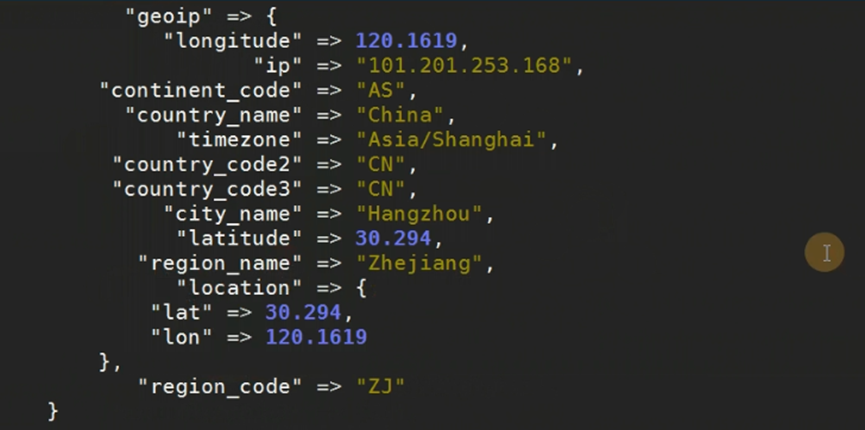
由于输出的内容太多,可以通过fileds选项选择自己需要的信息;
如下是一个示例配置
[root@es-node3 ~]# cat /etc/logstash/conf.d/grok_filter.conf
input {
http {
port => 7474
}
}
filter {
grok {
match => {
"message" => "%{COMBINEDAPACHELOG}"
}
}
geoip {
source => "clientip"
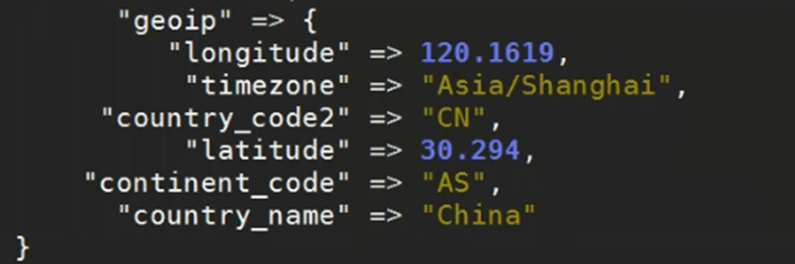
fields => ["country_name","country_code2","timezone","longitude","latitude","continent_code"] #仅提取需要的字段
}
}
output {
stdout {
codec => rubydebug
}
}
如下图可以看到少了很多信息
4.date插件
建议阅读:
https://www.elastic.co/guide/en/logstash/7.9/plugins-filters-date.html
Date插件将日期字符串解析为日志类型。然后替换@timestamp字段或指定的其他字段
match类型为数组,用于指定日期的匹配格式,可以以此指定多种日期格式
target类型为字符串,用于指定赋值的字段名,默认是@timestamp
timezone类型为字符串,用于指定时区域
如下图,@timestamp是日志的写入时间,timestamp是访问时间,我们在kibina筛选的字段是@timestamp,可能访问日志在同一时间写入了大量日志,没办法按照合适的时间筛选日志,所以需要将@timestamp用timestamp覆盖掉。
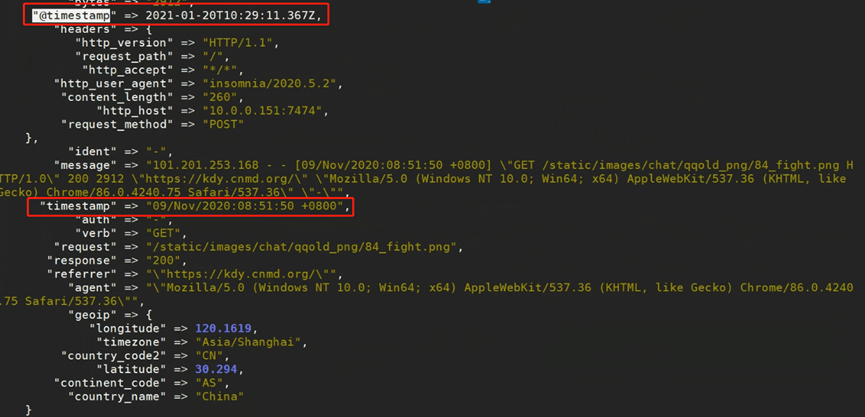
如下是一个配置文件示例
[root@es-node3 ~]# cat /etc/logstash/conf.d/grok_filter.conf
input {
http {
port => 7474 ###logstash监听的端口
}
}
filter {
grok {
match => {
"message" => "%{COMBINEDAPACHELOG}"
}
}
geoip {
source => "clientip"
fields => ["country_name","country_code2","timezone","longitude","latitude","continent_code"] #仅提取需要的字段
}
date {
# 09/Nov/2020:08:51:50 +0800
match => ["timestamp", "dd/MMM/yyyy:HH:mm:ss Z" ]
target => "nginx_date"
timezone => "Asia/Shanghai"
}
}
output {
stdout {
codec => rubydebug
}
}
5.useragent插件
Useragent插件根据请求中的user-agent字段,解析出浏览器设备、操作系统等信息;
以下是一个配置示例
[root@es-node3 ~]# cat /etc/logstash/conf.d/grok_filter.conf
input {
http {
port => 7474
}
}
filter {
grok {
match => {
"message" => "%{COMBINEDAPACHELOG}"
}
}
geoip {
source => "clientip" ###clientip需要在grok插件中有这个字段
fields => ["country_name","country_code2","timezone","longitude","latitude","continent_code"] #仅提取需要的字段
}
date {
# 09/Nov/2020:08:51:50 +0800
match => ["timestamp", "dd/MMM/yyyy:HH:mm:ss Z" ]
target => "nginx_date"
timezone => "Asia/Shanghai"
}
useragent {
source => "agent" ###字段来源
target => "user_agent" ###指定覆盖的字段,如果没有会新生成这个字段
}
}
output {
stdout {
codec => rubydebug
}
}
效果如下图
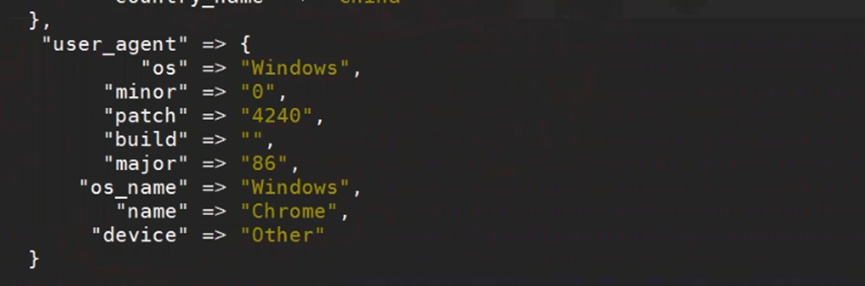
4.logstash filter插件之mutate插件
1.mutate插件介绍
mutate主要是对字段进行类型转换、删除、替换、更新等操作;
remove_field 删除字段
split 字符串切割
add_field 添加字段
convert 类型转换
gsub 字符串替换
rename 字段重命名
2.remove_field示例
[root@es-node3 ~]# cat /etc/logstash/conf.d/grok_filter.conf
input {
http {
port => 7474
}
}
filter {
grok {
match => {
"message" => "%{COMBINEDAPACHELOG}"
}
}
geoip {
source => "clientip" ###clientip需要在grok插件中有这个字段
fields => ["country_name","country_code2","timezone","longitude","latitude","continent_code"] #仅提取需要的字段
}
date {
# 09/Nov/2020:08:51:50 +0800
match => ["timestamp", "dd/MMM/yyyy:HH:mm:ss Z" ]
target => "nginx_date"
timezone => "Asia/Shanghai"
}
useragent {
source => "agent"
target => "user_agent"
}
mutate {
remove_field => ["headers","message"]
}
}
output {
stdout {
codec => rubydebug
}
}
可以看到少了很多字段
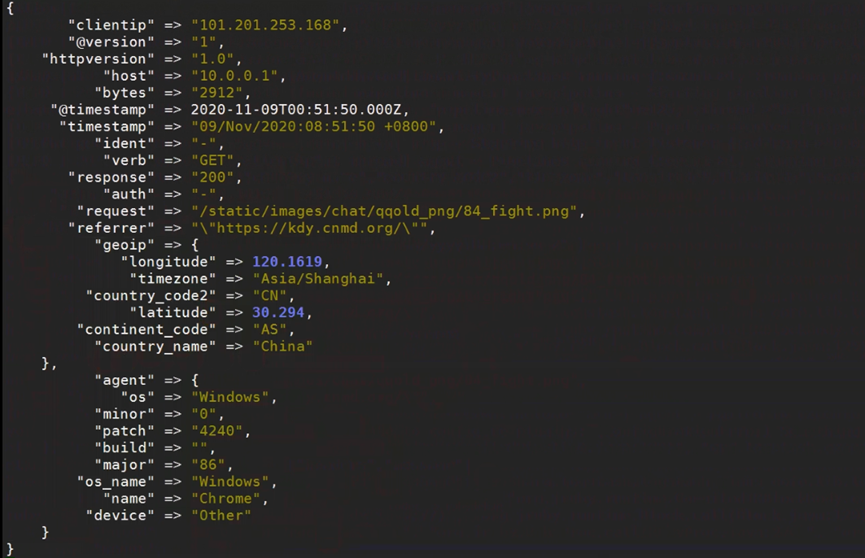
3.split示例
mutate中的split字符切割,指定|为字段分割符
测试数据:5607|提交订单|2020-08031
配置文件示例
[root@es-node3 ~]# cat /etc/logstash/conf.d/app_filter.conf
input {
stdin { ###插件类型为stdin
}
}
filter {
mutate {
split => { "message" => "|" }
}
}
output {
stdout {
codec => rubydebug
}
}
可以看到如下输出
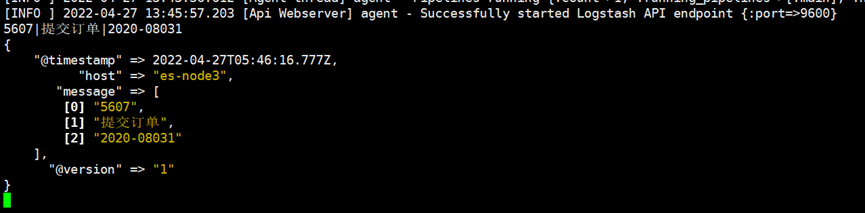
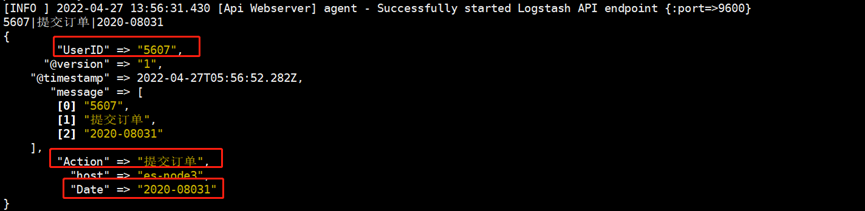
4.add_field示例
mutate中add_field可以将分割后的数据创建出新的字段名称。便于以后的统计和分析;
以下是一个配置示例
[root@es-node3 ~]# cat /etc/logstash/conf.d/app_filter.conf
input {
stdin { ###插件类型为stdin
}
}
filter {
mutate {
split => { "message" => "|" }
add_field => {
"UserID" => "%{[message][0]}"
"Action" => "%{[message][1]}"
"Date" => "%{[message][2]}"
}
}
}
output {
stdout {
codec => rubydebug
}
}
可以看到多了如下添加的字段
5.convert示例
mutate中的convert类型转换。支持integer、float、string等类型;
如下是一个配置文件示例
[root@es-node3 ~]# cat /etc/logstash/conf.d/app_filter.conf
input {
stdin { ###插件类型为stdin
}
}
filter {
mutate {
split => { "message" => "|" }
add_field => {
"UserID" => "%{[message][0]}"
"Action" => "%{[message][1]}"
"Date" => "%{[message][2]}"
}
convert => {
"UserID" => "integer"
"Action" => "string"
"Date" => "string"
}
remove_field => ["headers","message"]
}
}
output {
stdout {
codec => rubydebug
}
}
效果如下图

未经允许不得转载:孙某某的运维之路 » 4.Logstash日志处理快速入门

评论已关闭